AlphaGo 第1局 終局図 20160309
AlphaGo 第2局 終局図 20160310 div style="line-height: 9...
AlphaGo 第3局 終局図 20160312
AlphaGo 第4局 20160313
https://youtu.be/yCALyQRN3hw
https://youtu.be/yCALyQRN3hw?t=3h10m20s
第4局78手目
https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiNWI4pz98xe1qUCs9Db9h2RLMjujnZHt30S0atc-qzGlEmzkESRmnMQPpTJ6bYZH3Ejljw_rih6zUcflVG4pbReTSQdxlmk5Ftu1PfQH8eG6KQPfEphyphenhyphenQ70OOIRbHBHa9Adw0mjg/s640/blogger-image--1799271017.jpg
AlphaGo 第5局 終局図 20160315
AlphaGo まとめ
ディープラーニング
三村囲碁jp – 囲碁棋士九段
http://mimura15.jp/
棋譜ぅ|見ると囲碁が強くなる棋譜データベース
http://www.kihuu.net/
第5局
http://live.nicovideo.jp/watch/lv255280572
Match 5 - Google DeepMind Challenge Match: Lee Sedol vs AlphaGo - YouTube
https://m.youtube.com/watch?v=mzpW10DPHeQ
AlphaGo 第2局 終局図 20160310 div style="line-height: 9...
AlphaGo 第3局 終局図 20160312
AlphaGo 第4局 20160313
https://youtu.be/yCALyQRN3hw
https://youtu.be/yCALyQRN3hw?t=3h10m20s
第4局78手目
https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiNWI4pz98xe1qUCs9Db9h2RLMjujnZHt30S0atc-qzGlEmzkESRmnMQPpTJ6bYZH3Ejljw_rih6zUcflVG4pbReTSQdxlmk5Ftu1PfQH8eG6KQPfEphyphenhyphenQ70OOIRbHBHa9Adw0mjg/s640/blogger-image--1799271017.jpg
AlphaGo 第5局 終局図 20160315
NAMs出版プロジェクト: 碁の必勝法(ただし5路盤) | 配電盤
http://nam-students.blogspot.jp/2016/03/5.htmlAlphaGo まとめ
ディープラーニング
三村囲碁jp – 囲碁棋士九段
http://mimura15.jp/
棋譜ぅ|見ると囲碁が強くなる棋譜データベース
http://www.kihuu.net/
第5局
http://live.nicovideo.jp/watch/lv255280572
Match 5 - Google DeepMind Challenge Match: Lee Sedol vs AlphaGo - YouTube
https://m.youtube.com/watch?v=mzpW10DPHeQ
羽生善治三冠 特別講演「格言から学ぶ将棋」2013
http://nam-students.blogspot.jp/2017/06/2013.html
201706追記:
【爆笑】囲碁シチョウ やってみないとわからない 趙治勲 名誉名人 吉原由香里 六段
https://youtu.be/NuLKCF6PHR0
【アルファ碁】自己対戦棋譜【徹底分析】
https://youtu.be/7pZ65tegR7U
https://youtu.be/NuLKCF6PHR0
【アルファ碁】自己対戦棋譜【徹底分析】
https://youtu.be/7pZ65tegR7U
20170511追記:
スマホ版やねうら+elmo公開
http://shogidroid.siganus.com/engines.html
競技プログラマー向け将棋AI開発入門 - nodchipのTopCoder日記 - TopCoder部
http://topcoder.g.hatena.ne.jp/nodchip/20151224/1450969207https://deepmind.com/research/alphago/alphago-vs-alphago-self-play-games/
これやね10局あがってる
113名無し名人2017/05/27(土) 17:09:15.46ID:6GLy1662>>121>>126
今後について、
まず、今回の対局のアルファ碁の思考内容などを順次公開していきます。
またアルファ碁の自己対戦の棋譜(50局分)を近いうちに公開します。
世界中の囲碁ファンにとって、役に立てれば幸いです。
今年中には(今年後半には)アルファ碁に関する新たな論文を発表します。
去年の論文をもとに多くの人がそれぞれのバージョンのアルファ碁を作っていますが
今回の論文でさらに強いアルファ碁を作ってもらえると期待しています。
研究開発チームはアルファ碁のアルゴリズムをさらに発展させて汎用性のあるプログラム、
例えば病気の治療などに有用な人工知能を開発することに向かいます。
実際にどんなことができるようになるか、待ち遠しい気がしています。
2017
ネットに謎の囲碁棋士「Master」が出現 世界トップ棋士を続々撃破 - ねとらぼ
http://nlab.itmedia.co.jp/nl/articles/1701/03/news011.html
人工知能 Master(AlphaGo AI) vs 井山裕太九段 Iyama Yuta
https://youtu.be/7rXPw3IGg7c http://i.imgur.com/cdjBCC6.gifハーバート・サイモン(Herbert Alexander Simon)
http://nam-students.blogspot.jp/2016/03/herbert-alexander-simon.html
>囲碁の合法局面数はもう求まっていて、2.08*10^170
>将棋はだいたい10^68から10^67の間くらい。
手塚治虫愛のコスモゾーン冒頭を見ると実感できるのだが、人工知能は人間の教育に力を発揮するべきだろう。


囲碁を知らない子供が二人
二つのAIが半年教育する
子供が対戦し
勝った子供の教師AIが勝者
デバイスが大事になる
ハイライトは二つ
AlphaGo vs イ・セドル part43 [無断転載禁止]©2ch.net | 囲碁・オセロ板のスレッド | itest.2ch.net
http://tamae.2ch.net//test/read.cgi/gamestones/1457892399//?v=pc
Demis Hassabis
Just shows how deeply complex Go is.
Lee Sedol's move 78 in Game 4 and move 37 by #AlphaGo in Game 2 will be discussed for a very long time
Just shows how deeply complex Go is.
Lee Sedol's move 78 in Game 4 and move 37 by #AlphaGo in Game 2 will be discussed for a very long time
囲碁はなんて奥深いんだろう
4試合目のセドル78手目と2試合目AlphaGoの37手目が長い時間検討されるでしょう
Google DeepMind Challenge Match感想② – 三村囲碁jp
http://mimura15.jp/3007.html
Google DeepMind Challenge Matchの感想④ – 三村囲碁jp
http://mimura15.jp/3016.html
水平線効果(すいへいせんこうか)は探索アルゴリズムの深度を有限とした場合、それ以降の経路をあたかも水平線の向こうのように考慮しないため、長期的に見て問題のある選択をしてしまう人工知能における問題である。
問題点は二つ
m4-78手目を解説者含めて読めなかった
日本の囲碁のレベルが低い
水平線効果(ツリー構造の無駄に見える枝を切り捨てることから起こる弊害)の克服はかなり難しいと予想される
追記:
付け加えるなら計算関数、評価値、形成評価は社会的に決まるということ。半目勝ちでいいというAIの判断はgoogle内の事情だ。医学転用にはその議論が必要。
AlphaGoの場合は、モンテカルロ法+ディープラーニングと言われているが、重要なのはモンテカルロ法のチューニングやプログラミング技術の細かい所にあると思う。これがうまくできていたから自己対戦による学習が効果的に作用して、急速に強くなった。
問題は、その一番重要なモンテカルロ法のチューニングに成功した段階では、そのソフトはまだ相当弱いということだ。結果から見ると、そのソフトは、世界レベルのトッププロに勝つ将来が約束されていて、障害はほとんどないのだが、それは事前にはわからない。
知性とは何か AlphaGoの初戦で感じたこと - WirelessWire News(ワイヤレスワイヤーニュース)
https://wirelesswire.jp/2016/03/51084/
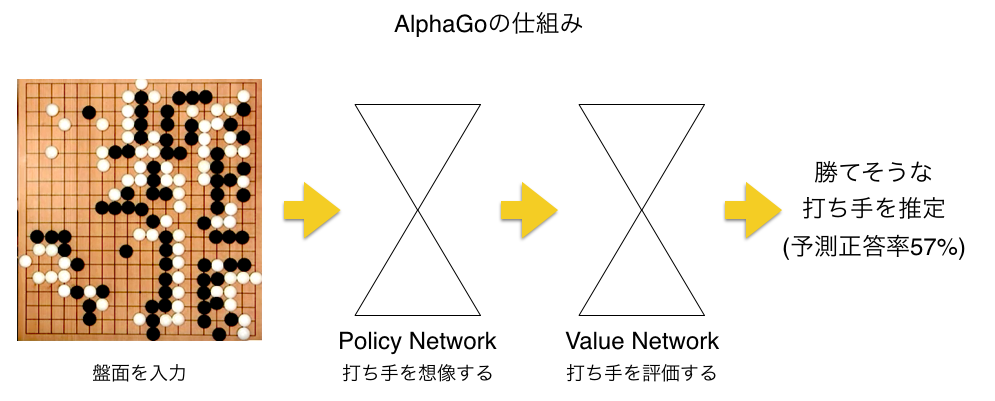
まず、AlphaGoの仕組みについて簡単に振り返ってみましょう。
AlphaGoを構成するのは打ち手を探索する「Policy Network」と局面を評価する「Value Network」という2つの深層ニューラルネットワークです。

ソースコードを読んでないので想像で補うしかありませんが、盤面からの入力に対してPolicy Networkで「次はこんな感じの手を打ったらいいんじゃないか」という確率を出し、出された確率のうち、上位数十から数百手に対して、次のValue Networkでその手を選択した場合の勝率はどのくらいかということを評価し、最も高い勝率が出せそうな手を選択するという二段構えの手法です。
しかも、Googleの主張によれば(http://googlejapan.blogspot.jp/2016/01/alphago.html)、予測される次の打ち手の正解率は57%と従来手法とくらべて極めて高く(従来手法では44%)、これが強さの秘密だと主張しています。
GoogleのAI研究チームDeepMindの論文によれば、入力として19×19の盤面全体に対して、白、黒、それ以外という3つの状態をそのまま入力した場合だけでも、予測的中率55.7%、それ以外の盤面に関わる情報、何手目か、アタっている石はどれか、などより詳細な情報を加えて学習させると、予測的中率が57%になった、とのことです。
これを繰り返すことで、Policy Networkで探索木の枝を適切に絞り込み、ValueNetworkで評価。この繰り返しで数手先を読み、最終的にどの手を選択すべきかということを決定します。
この仕組みの意味する最も重大なことは、普通の人間が囲碁をする場合とは異なり、論理性や定石といった記号化された知識を一切持っていないということです。
素人が囲碁をする場合、いろいろと本を読んで定石を勉強したりしながら、文字通り「頭を使って」手を選びます。
ところが、AlphaGoを含む人工知能の場合、そういうロジックを一切使用せずに、ニューラルネットワークに盤面のイメージやその他の情報を入力し、最終的に勝つか勝たないかということだけを評価関数としてひたすら学習を繰り返します。
これは仕組みとしてはかなりシンプルな部類です。これを学習させるために大規模な計算資源を使ったというだけで、仕組みそのものはノートPCにも入ってしまいそうな勢いです。
AlphaGoの場合、最先端のRNNすら使っていないのです。
参考:
日経 Robotics 2016年04月号
http://techon.nikkeibp.co.jp/ROBO/
AI最前線 <第9回> AlphaGo:CNNと強化学習を組み合わせた コンピュータ囲碁 全2頁
_____________
https://wirelesswire.jp/2016/03/51084/
まず、AlphaGoの仕組みについて簡単に振り返ってみましょう。
AlphaGoを構成するのは打ち手を探索する「Policy Network」と局面を評価する「Value Network」という2つの深層ニューラルネットワークです。
ソースコードを読んでないので想像で補うしかありませんが、盤面からの入力に対してPolicy Networkで「次はこんな感じの手を打ったらいいんじゃないか」という確率を出し、出された確率のうち、上位数十から数百手に対して、次のValue Networkでその手を選択した場合の勝率はどのくらいかということを評価し、最も高い勝率が出せそうな手を選択するという二段構えの手法です。
しかも、Googleの主張によれば(http://googlejapan.blogspot.jp/2016/01/alphago.html)、予測される次の打ち手の正解率は57%と従来手法とくらべて極めて高く(従来手法では44%)、これが強さの秘密だと主張しています。
GoogleのAI研究チームDeepMindの論文によれば、入力として19×19の盤面全体に対して、白、黒、それ以外という3つの状態をそのまま入力した場合だけでも、予測的中率55.7%、それ以外の盤面に関わる情報、何手目か、アタっている石はどれか、などより詳細な情報を加えて学習させると、予測的中率が57%になった、とのことです。
これを繰り返すことで、Policy Networkで探索木の枝を適切に絞り込み、ValueNetworkで評価。この繰り返しで数手先を読み、最終的にどの手を選択すべきかということを決定します。
この仕組みの意味する最も重大なことは、普通の人間が囲碁をする場合とは異なり、論理性や定石といった記号化された知識を一切持っていないということです。
素人が囲碁をする場合、いろいろと本を読んで定石を勉強したりしながら、文字通り「頭を使って」手を選びます。
ところが、AlphaGoを含む人工知能の場合、そういうロジックを一切使用せずに、ニューラルネットワークに盤面のイメージやその他の情報を入力し、最終的に勝つか勝たないかということだけを評価関数としてひたすら学習を繰り返します。
これは仕組みとしてはかなりシンプルな部類です。これを学習させるために大規模な計算資源を使ったというだけで、仕組みそのものはノートPCにも入ってしまいそうな勢いです。
AlphaGoの場合、最先端のRNNすら使っていないのです。
参考:
日経 Robotics 2016年04月号
http://techon.nikkeibp.co.jp/ROBO/
AI最前線 <第9回> AlphaGo:CNNと強化学習を組み合わせた コンピュータ囲碁 全2頁
_____________
「囲碁の謎」を解いたグーグルの超知能は、人工知能の進化を10年早めた « WIRED.jp
http://wired.jp/2016/01/31/huge-breakthrough-google-ai/
囲碁においては、最も強力なスーパーコンピューターですら、可能性のあるすべての手の結果を一定の時間内で分析するのに十分な処理能力をもたない。1997年にIBMが開発した「Deep Blue」がチェスチャンピオンのガルリ・カスパロフを倒したとき、コンピューターはいわば力づくで勝利をもぎとった。つまり、Deep Blueはすべての可能な手について総当りで計算し、どんな人間よりも先を読んだにすぎない。
こういったやり方は囲碁では不可能だ。チェスでは、どの局面でも平均で35通りの打ち方がある。これに対し、縦横19本の線が引かれた盤の上に石を並べて争う囲碁では、打ち方は250通りだ。そしてその250の打ち方それぞれについて次の250があり、これが続いていく。ハサビスが指摘するように、囲碁では宇宙に存在する原子よりたくさんの手数があるのだ。
NTTコムウェア | イノベーター : 第8回 人間の感性に近い判定が可能な画像識別システム
http://www.nttcom.co.jp/special/innovator/eighth/iv2/
http://www.nttcom.co.jp/special/innovator/eighth/iv2/


コレ一枚でわかるスマートマシン(4/4)進化する人工知能・ディープラーニング:ITソリューション塾:オルタナティブ・ブログ
http://blogs.itmedia.co.jp/itsolutionjuku/2014/12/post_25.html
http://blogs.itmedia.co.jp/itsolutionjuku/2014/12/post_25.html

ディープラーニングがもたらす横方向の格差拡大 (1/2)
http://blogos.com/article/166219/
AlphaGoの場合は、モンテカルロ法+ディープラーニングと言われているが、重要なのはモンテカルロ法のチューニングやプログラミング技術の細かい所にあると思う。これがうまくできていたから自己対戦による学習が効果的に作用して、急速に強くなった。
問題は、その一番重要なモンテカルロ法のチューニングに成功した段階では、そのソフトはまだ相当弱いということだ。結果から見ると、そのソフトは、世界レベルのトッププロに勝つ将来が約束されていて、障害はほとんどないのだが、それは事前にはわからない。
http://blogos.com/article/166219/
AlphaGoの場合は、モンテカルロ法+ディープラーニングと言われているが、重要なのはモンテカルロ法のチューニングやプログラミング技術の細かい所にあると思う。これがうまくできていたから自己対戦による学習が効果的に作用して、急速に強くなった。
問題は、その一番重要なモンテカルロ法のチューニングに成功した段階では、そのソフトはまだ相当弱いということだ。結果から見ると、そのソフトは、世界レベルのトッププロに勝つ将来が約束されていて、障害はほとんどないのだが、それは事前にはわからない。
深層学習(ディープラーニング)を素人向けに解説(後編)―特徴選びの重要性、機械はどうやって物事を理解するのか? | Stone Washer's Journal | ページ 2
http://stonewashersjournal.com/2015/03/07/deeplearning2/2/
機械がどのような過程で物を学び、情報を関連づけながら理解していくのかについては理解出来ました。しかし、ディープラーニングの説明がまだ始まっていません。
実は、ここまで来るとかなりゴールに近づいてきています。というのも、上述のニューラルネットワークが物を理解する過程というのはあくまで理想論であり、厳密にはこの域に達していないからです。ある意味、説明するべき段階を説明し終え、余計に説明したようなもの。
実は、ディープラーニングと言うのは小さなまとまりとして構成したニューラルネットワークの一つ一つに役割を与え、理解するべき内容を出来る限りシンプルにしてから理解させようという試みに過ぎないからです。
言わば、ニューラルネットワークで多数の班を作り、班ごとにシンプルな役割を与え、各班に順番にタスクをこなさせる学習方法がディープラーニングということです。
ただ、これの凄いところは、その役割の分担や理解すべき内容の単純化を機械自身が行えるという点にあります。
少し抽象的ですが具体的に言えば、
「写真を見たらとりあえず映像を小分けにして解析する」
「Wikipediaを読んだら段落ごとに分けて解析する」
みたいなものです。
そして、小分けにして解析したものに優先順位をつけつつ、情報の関連性を探っていきます。
http://stonewashersjournal.com/2015/03/07/deeplearning2/2/
機械がどのような過程で物を学び、情報を関連づけながら理解していくのかについては理解出来ました。しかし、ディープラーニングの説明がまだ始まっていません。
実は、ここまで来るとかなりゴールに近づいてきています。というのも、上述のニューラルネットワークが物を理解する過程というのはあくまで理想論であり、厳密にはこの域に達していないからです。ある意味、説明するべき段階を説明し終え、余計に説明したようなもの。
実は、ディープラーニングと言うのは小さなまとまりとして構成したニューラルネットワークの一つ一つに役割を与え、理解するべき内容を出来る限りシンプルにしてから理解させようという試みに過ぎないからです。
言わば、ニューラルネットワークで多数の班を作り、班ごとにシンプルな役割を与え、各班に順番にタスクをこなさせる学習方法がディープラーニングということです。
ただ、これの凄いところは、その役割の分担や理解すべき内容の単純化を機械自身が行えるという点にあります。
少し抽象的ですが具体的に言えば、
「写真を見たらとりあえず映像を小分けにして解析する」
「Wikipediaを読んだら段落ごとに分けて解析する」
みたいなものです。
そして、小分けにして解析したものに優先順位をつけつつ、情報の関連性を探っていきます。


AlphaGoはpolicy networkでモンテカルロ探索木を効率的に作って
形勢評価をvalue networkで行って手を決める、らしい
policy networkとvalue networkは両方ともディープラーニングのパターン認識
3局目まで形勢評価は人間以上と評されてきたわけだから
policy networkになんか問題があるんだろう
逆
モンテカルロを使うのは形勢評価でValueNectoworkと併用する
アルファに序盤で地合いで勝っていると錯覚させつつ、中盤にそれをひっくり返す長い手筋を仕込むのがアルファ碁を攻略するカギと思われる
セドルが過去3局でそれを見切り、二段バネを2回許して中央にキズを残しつつ地合い負けを演出し、アルファ碁が読み切れない中盤の手筋を仕込んだのだとしたら…
セドルもやはりバケモノだ
セドルが過去3局でそれを見切り、二段バネを2回許して中央にキズを残しつつ地合い負けを演出し、アルファ碁が読み切れない中盤の手筋を仕込んだのだとしたら…
セドルもやはりバケモノだ
- 0201 名無し名人 2016/03/14 06:31:13左右の2段バネは単純に戦いにもっていったら不利と判断しただけ
左辺はかかえた黒石にはさみつければ黒は簡単にしのげるのできりちがったら白があやしい
右辺はさすがに切ってほしかったが右辺だけでもあやしいから上辺への影響かんがえて我慢したんだろう
右辺白とりこまれたら地合いはとてもおいつかんし上辺切り離されたら実戦進行のようになる
あえて言うなら高く構えるべきだったか?というくらいか
5線のカタツキといいつなげて模様と化すうちまわしが厳しいときがおおかった返信 ID:BIVXhsxs(5)deepmindは強化学習でgoogleに買収されたようなもんだからな
It is apparent from the results that larger and deeper networks
have qualitatively better performance than shallow networks,
reaching 97% winning rate against GnuGo for a large 12-layer network compared to 3.4% for a small 3-layer network.
Furthermore, the accuracy on the supervised learning task is clearly strongly correlated with playing performance
あと大本の論文でこう書いてるから、もっとレイヤー増やしたの見たかった
imagenetでは152レイヤーとかになってるし- 0220 名無し名人 2016/03/14 07:02:45AlphaGoが李氏に一敗、「この敗北データはAIの学習のために非常に貴重」と開発者 - ITmedia ニュース
DeepMind創業者のデミス・ハサビス氏は李氏の勝利をたたえ、
「李氏は素晴らしい棋士で、今日はAlphaGoにとって強すぎた。この一敗はわれわれにとって非常に貴重なものだ。
この敗北のデータを持ち帰り、AlphaGoの今後の学習に役立てたい」と語った。
同氏は第3局を振り返り、李氏が78手で“ファンタスティックな一手”を打ったため、AlphaGoが79手目でミスを犯したが、それに気付いたのは87手目だったと語った。
同氏と共に記者会見に臨んだ開発者は、「AlphaGoを鍛えるために、優秀な対戦相手が必要だったので、この敗北には非常に意味がある。
今回のゲームを詳細に分析することで、AlphaGoをさらに改善できる」と語った。
韓国のプロ棋士、宋泰坤(Song Tae Gon)九段は「李氏はAlphaGoの動きをより良く把握したので、第5局はさらに接戦になるだろう。
プロ棋士たちは、AlphaGoの勝負を見て、これまで悪手とみなしてきたものを見なおそうとしている。
AlphaGoは囲碁の既成概念を打ち破る手助けをしてくれた」と語った。
第5局は15日の午後1時にスタートする。
ライブストリーミングはYouTubeのほか、囲碁プレミアムでは日本語解説付きで、ニコニコ生放送では実況番組を放送する。いずれも視聴は無料。ID:mKCzuddx(96)
AI不利になった途端バグ(みたいな動き)を繰り返し、イセドル勝利!!
囲碁プレミアム Google DeepMind Challenge Match: Lee Sedol〇 vs ◉AlphaGo match 4
http://youtu.be/aZtZdAaInEM
78手目、白(09k)の割り込みで白逆襲、それまではハネず、受けるだけ。
79手目(黒10J)?この時AI70%以上勝率(AIは割り込みに気付かないまま悪手)
AIは地を自陣と認識すると計算を楽にするために切り捨てる。87手目でAIが自軍不利に気付く
K9-78手目。次にalはJ10に指す。以下iPad用の文字仕様
ABCDEFGHIJKLMNOPQRS
01┏┳┳┳┳┳┳┳┳┳┳┳┳┳┳┳┳┳┓
02┣╋╋╋╋╋╋╋╋╋╋╋╋◉╋╋╋╋┫
03┣╋╋◉〇◉╋◉╋╋╋〇〇◉╋╋╋╋┫
04┣╋◉╋◉〇╋◉〇╋╋╋◉◉╋◉╋╋┫
05┣╋╋╋╋╋〇◉
日経ロボティクス4月号にAlphaGoの岡野原さん解説が載ってます。とてもタイムリーなので、先週論文読もうとして挫折した人はぜひ!pic.twitter.com/s0zDV7qMTC

Googleが人工知能AlphaGoと世界最強棋士の対局から学んだ2つのこと - GIGAZINE
http://gigazine.net/news/20160317-google-alphago/
Googleにより買収された人工知能開発ベンチャーの「DeepMind」が開発した人工知能ソフトウェアの「AlphaGo」は、今まで人工知能が勝てなかった囲碁で世界最強の棋士であるイ・セドル九段を打ち破るという快挙を成し遂げました。韓国で行われた囲碁界世紀の一戦では、人工知能が人間を上回ったという結果が出たわけですが、DeepMindを率いるデミス・ハサビス氏は人工知能の勝利は全ての人類にとって大きな利益があることを強調しています。
Official Google Blog: What we learned in Seoul with AlphaGo
https://googleblog.blogspot.jp/2016/03/what-we-learned-in-seoul-with-alphago.html
2016年3月9日から3月15日まで行われたAlphaGoとイ・セドル九段の5局勝負は、AlphaGoの4勝1敗という形で決着がつきました。世紀の一戦はライブ中継で世界中に届けられ、Googleで囲碁のルールや碁盤など囲碁関連の検索数が爆発的に増えたり、韓国で囲碁人気に火がついたり、中国のソーシャルメディアのWeiboでハッシュタグ「Man vs. Machine Go Showdown」が2億ページビューを突破したりなど、大きな注目を集めていました。
多くの人の興味は「人工知能VS人間、勝つのはどちらか」という構図に向いていましたが、AlphaGoの開発者でもあるハサビス氏にとっては人工知能の勝利だけが求めていたことではありません。Googleに買収される前、ハサビス氏がDeepMindを設立したのは、自ら学習し最終的には環境問題や病気の診断など人間や社会を取り巻く問題を解決するツールとして人工知能を開発するためでした。
AlphaGoは、人間の神経回路を模倣してデータ分類を行うニューラルネットワークを用いた「ディープラーニング」と、ある行動を試行しその結果で得られる利益からより良い行動を学習する「強化学習」を使って開発されたソフトウェアです。2016年1月に初めて公にされたAlphaGoの最大の挑戦として掲げられたのが、ボードゲームの中で最も複雑と言われる囲碁の最強棋士であるイ・セドル九段との囲碁対決でした。
AlphaGoは、囲碁のコメンテーターが「予測不可能」「クリエイティブ」「美しい」と称賛する一手をイ・セドル九段との対局で打ってきました。DeepMindの対局データによると、第2局でのAlphaGoの37手目は、人間が打つ可能性は0.001%と分析された一手です。一方で、イ・セドル九段が第4局で放った78手目も人間が打つ可能性は0.001%と分析されています。イ・セドル九段は、第1局の対局後に「序盤におけるAlphaGoの戦略は卓越しており、AlphaGoは人間が打たないであろう普通ではない手を打った」とコメントを残しています。

ハサビス氏はAlphaGoとイ・セドル九段の対局で得たものは2つあるとしています。1つは、さまざまな問題を解決する人工知能の能力をテストできたこと。AlphaGoは碁盤全体に視野を広げ、プロの棋士が打ってはいけないと教えられた、もしくは打とうと考えもしなかった手を打ちました。これは、人工知能が人間の能力では思いつかないほど創造的な問題解決能力を持っているということで、人工知能を囲碁ではない他の分野でも活用できる可能性が多いにあります。
2つ目は、対局が「人間VS機械」という目線で語られているものの、AlphaGoは人間が作ったものであり、AlphaGoの勝利は人間の功績ということ。AlphaGoとイ・セドル九段は新しいアイデアの一手や、問題を解決するための一手を対局で放ち、これは長期的目線で捉えると、人間に大きな利益をもたらすと考えられます。
ただし、韓国では囲碁において「勝っても負けても思い上がってはいけない」と言われるように、ハサビス氏は今回の勝利が人工知能にとって小さな一歩に過ぎないことも強調しています。人間が頭を使って行うタスクを人工知能がこなせるようになるにはまだまだ時間がかかるそうです。

 | World Economic Forum (@wef) |
|
Is Google DeepMind's Go win a turning point for #AI research? wef.ch/1QXfOz3@demishassabis #technology pic.twitter.com/Q1qu9K4RJN
| |
AlphaGoの論文を日本語に訳してまとめてみた!(まだまだ未完成) - MATHGRAM

AlphaGo の論文をざっくり紹介 - technocrat
http://technocrat.hatenablog.com/entry/2016/03/14/011152AlphaGo の論文をざっくり紹介
元ネタはNature論文です。
http://www.nature.com/nature/journal/v529/n7587/full/nature16961.html
とても読みやすい論文だと思います。
オープンアクセス版もどっかに転がってたと思います。
http://www.nature.com/nature/journal/v529/n7587/full/nature16961.html
とても読みやすい論文だと思います。
オープンアクセス版もどっかに転がってたと思います。
構成要素
教師あり方策ネットワークp_\sigma
状態s(盤面の石配置など)を入力とし、次の手a(どこに石を置くか)を確率としてp(a|s)の形で返す関数です。
具体的には、13層の畳み込みニューラルネットワーク(CNN)を使い、最終層の出力結果を
ソフトマックス関数にかけて確率解釈しています。
KGSという碁の棋譜が保存されているサーバがあるそうで、そこから3千万のサンプルを教師として使い、
ネットワークをトレーニングしました。
つまり人間の指し手を教師とし、いかに模倣するかというネットワークですね。
具体的には、13層の畳み込みニューラルネットワーク(CNN)を使い、最終層の出力結果を
ソフトマックス関数にかけて確率解釈しています。
KGSという碁の棋譜が保存されているサーバがあるそうで、そこから3千万のサンプルを教師として使い、
ネットワークをトレーニングしました。
つまり人間の指し手を教師とし、いかに模倣するかというネットワークですね。
結果、57.0%の確率で、人間の指し手を模倣できるCNNができました。
一見低いような気がしますが、それ以前の手法では44.4%の正解にとどまっていたようですし、
実際人間の指し手も多様なので57.0%はすごいみたいです。
一見低いような気がしますが、それ以前の手法では44.4%の正解にとどまっていたようですし、
実際人間の指し手も多様なので57.0%はすごいみたいです。
このCNNは計算に3msかかるのですが、より精度を落として高速化を狙ったネットワーク
p_\piも用意されています。
p_\piは24.2%の再現度ですが、1回の推論が2マイクロ秒です。
p_\piはモンテカルロ計算の時に良い働きをします。
p_\piも用意されています。
p_\piは24.2%の再現度ですが、1回の推論が2マイクロ秒です。
p_\piはモンテカルロ計算の時に良い働きをします。
強化学習方策ネットワークp_\rho
教師ありネットワークp_\sigmaの重みを初期値とし、自分自身と対戦させ、より勝利できるようパラメータを
更新していってできたCNNがp_\rhoです。
更新していってできたCNNがp_\rhoです。
強化学習としても手法はかなりシンプルで、ある局面sで行動aを行った時、その方策CNNが勝利した場合、
aから終局までの行動系列の確率が大きくなるように、p_\piの勾配を利用してパラメータを更新します。
敗北の場合は、同様に確率が小さくなるように勾配を使ってパラメータの更新を行います。
aから終局までの行動系列の確率が大きくなるように、p_\piの勾配を利用してパラメータを更新します。
敗北の場合は、同様に確率が小さくなるように勾配を使ってパラメータの更新を行います。
こうしてできたCNN p_\rhoはそれ自身強く、教師ありCNNのp_\sigmaと戦わせて8割以上勝ち越し、
アマ2段にランクされるプログラムPachiに対して85%で勝ったようです。
アマ2段にランクされるプログラムPachiに対して85%で勝ったようです。
状態価値関数ネットワークv(s)
vはp_\rhoと良く似ていますが、指し手を返すのではなく、局面sに対してその価値を返します。
理想的には、ある局面sに対し、p_\piに従った手を指し続けた場合の勝利の期待値がAlphaGO流のv(s)です。
しかしその計算は大変なので、実際には、p_\pi 同士を戦わせて得られた3000万の局面と勝敗データを利用して学習を行いました。
理想的には、ある局面sに対し、p_\piに従った手を指し続けた場合の勝利の期待値がAlphaGO流のv(s)です。
しかしその計算は大変なので、実際には、p_\pi 同士を戦わせて得られた3000万の局面と勝敗データを利用して学習を行いました。
モンテカルロ探索
以上の構成要素を元に、実際に局面sに対してどのように手aを出すかはモンテカルロ法に基づきます。
状態sに対し、手aはQ(s,a)+u(s,a)の大きさで評価されます。
Q(s,a)はモンテカルロ計算の度にアップデートされる評価関数(後述)で、uはボーナス項と呼ばれています。
状態sに対し、手aはQ(s,a)+u(s,a)の大きさで評価されます。
Q(s,a)はモンテカルロ計算の度にアップデートされる評価関数(後述)で、uはボーナス項と呼ばれています。
u\propto p_{a|\sigma}/(1+N(s,a))という形をしており、教師あり学習CNNの出力p_\sigma*1に比例して、
手aが選ばれやすくなっており、妥当な事前確率分布になっています。
一方N(s,a)は、探索中に局面sでaを打つという状況に遭遇した回数であり、
なるべく広く探索を行うようにバイアスをかける項になっています。
手aが選ばれやすくなっており、妥当な事前確率分布になっています。
一方N(s,a)は、探索中に局面sでaを打つという状況に遭遇した回数であり、
なるべく広く探索を行うようにバイアスをかける項になっています。
Q(s,a)は、シミュレーション中に(s,a)の組に対して与えられた評価V(s,a)を算術平均して求めます。
具体的には、状態sから、有限の深度Lまで、最も評価関数(Q+u)の大きくなる手を打ち続けます。深度Lで辿り着いた局面をs_Lとしましょう。
s_Lは2つの異なる方法で評価されます。
まずは状態評価CNN v(s)です。v(s_L)がs_Lの評価値を与えます。
もう1つは、状態s_Lからスタートし、高速な方策CNNであるp_\piを用いて主局までゲームを行い、
勝ったか負けたかで評価値z_Lを得る方法です。
実際にAlphaGoが採用したのは、それらの平均、 V(s,a)=1/2 v(s_L) + 1/2 z_L です。
このようにして、シミュレーションの度にQ関数をアップデートし、時間の許す限りtree searchを行います。
(実際にはもう少し、探索深度を動的に伸ばすなどの工夫もありますが、この解説ではパスします。)
具体的には、状態sから、有限の深度Lまで、最も評価関数(Q+u)の大きくなる手を打ち続けます。深度Lで辿り着いた局面をs_Lとしましょう。
s_Lは2つの異なる方法で評価されます。
まずは状態評価CNN v(s)です。v(s_L)がs_Lの評価値を与えます。
もう1つは、状態s_Lからスタートし、高速な方策CNNであるp_\piを用いて主局までゲームを行い、
勝ったか負けたかで評価値z_Lを得る方法です。
実際にAlphaGoが採用したのは、それらの平均、 V(s,a)=1/2 v(s_L) + 1/2 z_L です。
このようにして、シミュレーションの度にQ関数をアップデートし、時間の許す限りtree searchを行います。
(実際にはもう少し、探索深度を動的に伸ばすなどの工夫もありますが、この解説ではパスします。)
____
Alpha Goの話 - 発声練習
http://next49.hatenadiary.jp/entry/20160315/1457970500Alpha Goの話
Google DeepMind社が開発しているAlpha Goの論文を読んでみたけど、うっすらとしか理解できない。機械学習の知識が足りない。stochastic gradient descentとstochastic gradient ascentってなんだよ!なんかの必殺技にしか見えない。いろいろ調べながら読んでみると、コンピュータ囲碁が劇的に強くなった原因であるモンテカルロ木探索におけるプレイアウト(Natureの論文だとrollout)時の打ち方(Policy network)とモンテカルロ木探索のノードの評価値(value network)を決めるところに畳み込みニューラルネットワークを使った深層学習を適用しているらしい。モンテカルロ木探索については情報処理学会学会誌「情報処理」の以下の記事がわかりやすかった。
- 美添一樹: モンテカルロ木探索-コンピュータ囲碁に革命を起こした新手法, 情報処理 (49) 6, 2008年
- David Silver, D. et al.: Mastering the game of Go with deep neural networks and tree search, Nature (529) 7587, pp. 484–489, 2016.
上記の論文を読む限り、モンテカルロ木探索はプレイアウトができる問題(ランダムに打って終局する。コマの評価値が均等など)で効果を発揮するものなので、Alpha Goがプロ棋士に勝ったからといって、すぐに人間が人工知能に支配されるという話じゃなさそう。どちらかというとこちらの話の方がびっくりぽん。こちらは強化学習に多層ニューラルネットワークを利用した様子。人間レベルの汎用人工知能の実現に向けた展望にある汎用人工知能(Artificial General Intelligence, AGI)実現のためのロードマップの一歩目「汎用ビデオゲーム学習」を踏襲していて怖い(というか、それを理解した上でやっているんだろうけど)。
- Mnih, V. et al.:Human Level Control Through Deep Reinforcement Learning, Nature (518) 7540, Letters, pp. 529–533, 2015
- Google Deepmind、人工知能『DQN』を開発。レトロゲームを自力で学習、人間に勝利
- Googleの自己学習する人工知能DQNを開発した「ディープマインド」の実態、何が目的なのか?
- Adams, S. et al.: Mapping the Landscape of Human-Level Artificial General Intelligence, AI magazine (33)1, 2012.:汎用人工知能の実現へ向けた課題や評価方法の提案
関連記事
- Gigazine: 囲碁チャンピオンを打ち破ったGoogleの人工知能「AlphaGo」を作った天才デミス・ハサビスが人工知能を語る
- A級リーグ指し手1号:AlphaGoが誇大広告ぎみな件:イ・セドル戦前のNature論文の解説。この解説に反して、AlphaGoがイ・セドル氏に勝ったのはPolicy NetworkおよびValue Networkの効果が予想以上だったのではないかと。たぶん、コンピュータ囲碁にも囲碁そのものにも素人の意見だけど、囲碁の打ち方の空間はこれまで人類が想像していたよりもはるかに広かったのだろうと思う。
- イ・セドル氏との5番勝負関連
- 人工知能学会学会誌「人工知能」の関連特集:日本語なのがありがたい。
- 特集「汎用人工知能(AGI)への招待」:人工知能 29(3)
- 人工知能学会誌 連載解説「Deep Learning(深層学習)」
- 深層学習 Deep Learning (監修:人工知能学会) :上の解説記事の単行本版。所属学科の先生がみんな買っているので事務の人に「みなさん買っていらっしゃいますけど、そんなに面白いんですか?」と質問される事態に。
【ニコ生(2017-06-12 20:00開始)】
【囲碁】棋界騒然!?AlphaGo自己対戦棋譜を徹底分析
http://nico.ms/lv300049344
【囲碁】棋界騒然!?AlphaGo自己対戦棋譜を徹底分析
http://nico.ms/lv300049344
>>520
レスthanks
タイムシフトで視聴してみた
テーマ毎に解説されていてわかりやすかった
https://deepmind.com/research/alphago/alphago-vs-alphago-self-play-games/
9,32(テーマ:ツケヒキ定石)
30,27(テーマ:三々)
1(テーマ:手抜き)
【囲碁】棋界騒然 AlphaGo自己対戦棋譜を徹底分析
次回も期待したくなった
(もともとトーナメント用の)コミをなくし、白黒二試合にした方が最善手を目指すから面白いというのはその通り。

52 Comments:
【将棋】技巧を使って三浦九段の疑惑の対局を検証してみる - YouTube
https://m.youtube.com/watch?v=hniCrGJ2YaQ%3Ft%3D12m38s
http://hayabusa8.2ch.net/test/read.cgi/mnewsplus/1483712241/-100
【囲碁】<プロ棋士はもはや囲碁AIに勝てない>進化型アルファ碁「Master」の衝撃!トッププロ相手に60戦60勝©2ch.net
1 : Egg ★@無断転載は禁止 ©2ch.net2017/01/06(金) 23:17:21.20 ID:CAP_USER9
「囲碁AI(人工知能)はプロ棋士の能力を遥かに超えてしまった。さらに進化が進み追いつくことはできないだろう」。囲碁AIにくわしいプロ棋士の大橋拓文六段はJ-CASTニュースのインタビューにそう語った。
「Master」と名乗る「人物」が中国の囲碁対戦サイト「野狐囲碁」で確認されたのは2016年12月29日。あまりの強さから大人気マンガ「ヒカルの碁」の登場人物・サイ(藤原佐為)ではないのか、などと取り沙汰されたが、グーグルは日本時間の17年1月5日、自社が開発した囲碁AIだと公表した。既に世界のトッププロ相手に60連勝していて、かなう棋士はもういないのだという。
■16年末にネットに忽然と現れる
チェス、将棋などトッププロを撃破するAIが登場しても、囲碁だけは打ち手が複雑なため人間を超えられないだろう、というのが長い間の定説だった。それを覆したのが16年3月中旬に行われたグーグル傘下の会社が開発した人工知能「アルファ碁(AlphaGo)」と、韓国の世界のトッププロ、イ・セドル九段との対戦で、1勝4敗で敗れるという波乱が起きた。
しかし、これ以降、なぜか「アルファ碁」は影を潜める。グーグルが囲碁AIに関する論文を公表していたことから、それを参考に「アルファ碁」に追いつこうと、新たな囲碁AI開発ラッシュが始まった。囲碁対戦サイトでは現在、中国の「刑天」など複数の囲碁AIが対戦をしていて、勝率は9割というものも出ている。
そして、16年末に忽然と現れたのが「Master」を名乗る「人物」だった。主に中国の囲碁サイト「野狐」に出没し、誰も敵わず勝率は100%だった。その噂を聞き、世界のトッププロが次々に挑戦することになるわけだが、そもそもプロ棋士がこうした場で非公式対戦をしているのはなぜなのだろうか。
トッププロ相手に60戦60勝
大橋六段によれば、プロ棋士ならば多くが対戦サイトにアカウントを持っていて、実名で登録している人もいる。また、実名でなくともトッププロであることを示すマークを付けていたりする。それは強いプロほど強い相手と対戦したいという欲求があるからで、柔道で言えば「乱取り」感覚の対戦となる。
トッププロとの対戦で「Master」は勝ち続け、17年1月1日の段階で30連勝、5日までに60連勝と勝率は100%となった。では「Master」とは誰なのか。ネット上ではあまりの強さに「ヒカルの碁」のサイだと持てはやされたが、囲碁の強い人でも最高勝率はだいたい6割で、それを上回る場合はAIを疑うのだという。
「Masterが10勝した時点では、誰かが破るだろう、という雰囲気でしたが、30勝を超えると、こりゃあだめだなといった諦めムードが出て、50勝でもうお手上げ、という感じでしたね」
と、対戦を見ていた大橋六段は打ち明ける。負け知らずのためAIだということは最初から気付いていた、ともいう。
そして、グーグルは17年1月5日、「Master」は「アルファ碁」の進化型であることを公表した。今までそれをなぜ隠していたのか。16年3月に行われた「アルファ碁」とイ・セドル九段との対戦で、グーグルは1敗もしない完全勝利を確信していたのではないか、と大橋六段は予想している。
1敗のショックから「アルファ碁」を公の場から外し更なる開発を進めたのではないか、というのだ。「Master」は勝率100%で、トッププロから60連勝したことで、胸を張ったのだろうという。その「Master」との対戦はどのようなものなのだろうか。
つづく
J-CASTニュース 1/6(金) 17:20配信
http://headlines.yahoo.co.jp/hl?a=20170106-00000004-jct-ent&;p=1
2 : Egg ★@無断転載は禁止 ©2ch.net2017/01/06(金) 23:17:32.34 ID:CAP_USER9
人間では理解できない領域の打ち手が30手まで続く
プロ同士の戦いならば、対戦相手の性格、癖、プレイスタイルなどを把握していて、挑発や奇襲といった駆け引きが存在する。そして実力とは別にその日の体調、威圧感やオーラのようなものも影響してくるが、そうしたものは「Master」にはない。一直線に勝利に突き進んで来る。囲碁はおよそ200手で決まるものだが、大橋六段は、
「人間では理解できない領域の打ち手が30手まで続く。不思議といい場所に碁石があるね、というイメージだ」
と説明し、30手までに「これはおかしい」と不安になり、50手で「ヤバイ」、100手で「大差で負ける」。最後は「お稽古してもらっている」気分になった、という。
それでもいつかはテレビゲームのように攻略法が見つかるのではないのか、と聞くと、
「無理なのではないでしょうか」
と大橋六段は語った。例えば現在5歳の囲碁の天才に囲碁AIの棋譜を記憶させ続ければ10歳の頃には攻略は可能になるかもしれないが、それは5年前の囲碁AIの性能に対する攻略であり、囲碁AIはさらに遥か先に進化しているからだという。
「絶対に勝てないからといってAI鬱、AIシンドロームなどと落ち込む必要はなく、囲碁界はこれからいかにAIを活用して全体を盛り上げていく道を探り、明るい関わり方をしていかなければならないと感じています」
そう大橋六段は話している。
AIは教育に使わないと
囲碁を知らない子供が二人
二つのAIが半年教育する
子供が対戦し
勝った子供の教師AIが勝者
AIは教育に使わないと
>と大橋六段は語った。例えば現在5歳の囲碁の天才に囲碁AIの棋譜を記憶させ続ければ10歳の頃には攻略は可能になるかもしれないが、
>それは5年前の囲碁AIの性能に対する攻略であり、囲碁AIはさらに遥か先に進化しているからだという。
囲碁を知らない子供が二人
二つのAIが半年教育する
子供が対戦し
勝った子供の教師AIが勝者
837 : 名無しさん@恐縮です@無断転載は禁止2017/01/07(土) 05:29:29.62 ID:Z3e9fQlB0
AIは教育に使わないと
>と大橋六段は語った。例えば現在5歳の囲碁の天才に囲碁AIの棋譜を記憶させ続ければ10歳の頃には攻略は可能になるかもしれないが、
>それは5年前の囲碁AIの性能に対する攻略であり、囲碁AIはさらに遥か先に進化しているからだという。
囲碁を知らない子供が二人
二つのAIが半年教育する
子供が対戦し
勝った子供の教師AIが勝者
デバイスが大事になる
参考:
火の鳥愛のコスモゾーン
https://1.bp.blogspot.com/-a3riPKt2c6g/Vz1-wT_uo5I/AAAAAAAA-7o/-2h_PEzflFIn4Jln2U-JewUmf7T5tEtKACLcB/s1600/hinotori2772a.gif
>>217
大橋拓文
?@ohashihirofumi
ちょっと前にコミなし碁の復活を提案する、と書きました。
これからその理由を述べたいと思います。
きっかけはMasterの碁を見て、歴史上の名人達と似ている!と思ったことでした。
こう思われた方は僕だけではないでしょう。ではなぜ似ているのでしょうか?
Masterの序盤からの肩ツキ連打は呉先生のようです。
サバキの躍動感は道策に似ています。
見合い感覚は秀栄っぽいし小目近辺の重視の仕方は秀甫に通ずるものがあります。
ところが現代碁で誰かに似ているかと言われても思い当たりませんでした。
そこで閃いたのがコミの存在です。
もともと囲碁にはコミがありません。
近代になりトーナメントで一番で勝負を決める為に作られたのがコミです。
江戸時代の名人は時代の最強者ですからいつもコミなし碁で白を持っていました。
コミなし碁では先着する黒が有利です。
そこで歴代名人達は必然的に石の効率を極限まで追求しました。
翻って現代碁はどうでしょうか?
コミがあるため対等の条件です。
すると石の効率を極限まで追求するのはリスクも高いですから、無難に均衡を保ち部分戦のテクニックで勝つ方が安全に見えてしまうのです。
ゲーム的にはコミありで対等の方が良いですが、コミなし碁の方が効率に敏感になれるのです。
Masterの碁を見て、人間の囲碁の進化は正しかったのだろうか?というコメントがありましたが、
コミあり碁に慣れて相手に勝つことだけを追求しすぎてしまったのかもしれません。
コミなし碁であれば黒が勝って当たり前、すると不思議なもので囲碁の真理を謙虚に追求する心持ちになれるのでしょう。
【囲碁】AI vs 世界トップ棋士 Part 6 【AlfaGo/Master/刑天等】 [無断転載禁止]©2ch.net
345 :
名無し名人
2017/01/08(日) 20:04:49.51 ID:uvzDdPEt
__ A B C D E F G H I J K L MN OP Q R S
01┏┯┯┯┯┯┯┯┯┯┯┯┯┯┯┯┯┯┓
02┠┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┨
03┠┼┼┼┼●┼┼┼┼┼┼┼┼○┼┼┼┨
04┠┼┼○┼┼┼┼┼╋┼┼┼┼┼╋●┼┨
05┠┼┼┼★┼┼┼┼┼┼┼┼┼┼┼┼┼┨
06┠┼┼○┼┼┼┼┼┼┼┼┼┼┼┼┼┼┨
07┠┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┨
08┠┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┨
09┠┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┨
10┠┼┼╋┼┼┼┼┼╋┼┼┼┼┼╋┼┼┨
11┠┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┨
12┠┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┨
13┠┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┨
14┠┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┨
15┠┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┨
16┠┼○╋┼┼┼┼┼╋┼┼┼┼┼●┼┼┨
17┠┼┼┼●┼┼┼┼┼┼┼┼┼┼┼┼┼┨
18┠┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┨
19┗┷┷┷┷┷┷┷┷┷┷┷┷┷┷┷┷┷┛
観戦者A (今のMasterの一手は……?どういう意図だ!?)
申真? (コイツノ今ノ手ハ失着ダ) パチ
観戦者B (何やってんだ?おいMaster、そりゃうまくねーだろ)
観戦者A (どうした?勘違い?それともやはりこれが実力?)
観戦者C (Master……)
Google (誰もMasterの狙いに気付いていない
今ここにいる誰よりもMasterは上をいっている)
__ A B C D E F G H I J
01┏┯┯┯┯┯┯┯┯┯
02┠┼┼●┼┼┼┼┼┼
03┠┼●┼┼●●┼┼○
04┠┼┼○┼○┼┼┼╋
05┠┼┼○●┼┼┼┼┼
06┠┼┼○┼┼┼┼┼┼
07┠┼┼┼┼┼┼┼┼┼
08┠┼○○●┼┼┼┼●
09┠┼○●┼┼┼○┼●
10┠┼┼╋●┼●○┼●
申真? (ウッ!悪手ダッタハズノサッキノ一手ガ――
コ……ココニキテ絶好ノ位置ニイル!)
観戦者C (Masterの悪手と思われたあの一手は左上の攻防をニラんでの手だったのか!)
113KB
新着レスの表示
인공지능 마스터 알파고 vs 신진서 6단 바둑 기보 Master(AlphaGo AI) vs Shin Jinseo 6p 申眞諝 六段 囲碁棋譜 人工知能 人機大戰 圍棋棋局 人机大战 围棋
https://youtu.be/A2r_01fmOsA
Master Game n°57: AlphaGo (Black) vs Shin Jin Seo (White), B+R.
https://youtu.be/PaFRdak9JrM
謎の囲碁棋士「Master」の正体は「AlphaGo」 Googleが発表 - ねとらぼ
http://nlab.itmedia.co.jp/nl/articles/1701/05/news031.html
Google DeepMindの共同創立者であるデミス・ハサビス氏が1月5日(日本時間)、Twitterを更新。年末年始に世界のトップ棋士を続々撃破していた謎の囲碁アカウント「Master」は、囲碁ソフト「AlphaGo」の新バージョンだと明らかにした。
声明によると、同社ではAlphaGoの改善作業に取り組んでおり、ここ数日はネット上で非公式のテストを行っていたという。「東洋囲碁と野狐囲碁で『Magister』『Master』と対戦した方、そして観戦して楽しんでもらった皆さんに感謝します」。テストが完了したことで、今後は囲碁の団体・専門家と協力して、2017年内に本格的な(持ち時間の多い)“公式戦”を実施するとしている。
Master
無敗のMaster
囲碁アカウント「Master」の戦績は、「野狐囲碁」で30勝0敗、東洋囲碁を含めると60勝0敗。テストの最終局の相手となった古力九段(中国のトップ棋士)は「人間とAIは共同で、間もなく囲碁の深い謎を解き明かす」とコメントしている。
Master
声明
世界1位の柯潔九段は入院
最終局は当初、柯潔九段が行う予定だったもよう
関連商品
Superintelligence: Paths, Dangers, StrategiesSuperintelligence: Paths, Dangers, StrategiesAmazon.co.jpで買う
(高橋史彦)
関連記事
ネットに謎の囲碁棋士「Master」が出現 世界トップ棋士を続々撃破ネットに謎の囲碁棋士「Master」が出現 世界トップ棋士を続々撃破
井山六冠とみられる人物との対戦は4000人が見守った
謎の囲碁棋士「Master」、中国・韓国1位の棋士にも勝利謎の囲碁棋士「Master」、中国・韓国1位の棋士にも勝利
前日には井山裕太六冠とみられる人物を撃破。
囲碁AI vs プロ棋士 世紀の5番勝負が終結 結果は「AlphaGo」の4勝1敗囲碁AI vs プロ棋士 世紀の5番勝負が終結 結果は「AlphaGo」の4勝1敗
「AlphaGo」は世界ランク4位、韓国名誉九段に。
囲碁AI「AlphaGo」が美少女に 韓国の絵師たちが擬人化イラストを続々投稿中囲碁AI「AlphaGo」が美少女に 韓国の絵師たちが擬人化イラストを続々投稿中
いいぞもっとやれ!
担当者遊んでるだろ! 囲碁の公式ニコ生で応援している人を両棋士と記録係から選べる斬新なアンケート担当者遊んでるだろ! 囲碁の公式ニコ生で応援している人を両棋士と記録係から選べる斬新なアンケート
結果は見え見え。
この記事の関連情報
関連リンク
Demis Hassabis氏のTwitter
Copyright© 2017 ITmedia, Inc. All Rights Reserved.
アルファ碁の強さとは 深層学習で身につけた「大局観」 -- 人工知能を愛せますか? -- 朝日新聞GLOBE
http://globe.asahi.com/feature/side/2017010600001.html
アルファ碁の強さとは 深層学習で身につけた「大局観」
人工知能(AI)に関する昨年の最大のニュースはなにか。多くの人が、英ディープマインド社の囲碁AI、「アルファ碁」が、世界のトップ棋士をやぶったことをあげるでしょう。20年前にはチェスの世界チャンピオンに勝ち、将棋でもプロ棋士の棋力をつけたといわれるAIですが、盤面が広く、はるかに多様な打ち方ができる囲碁では、「あと10年はかかる」といわれていたからです。
デミス・ハサビスCEOのツイート
この年末年始、ネット上の中国の囲碁サイトで、世界のトップ棋士を相手に連戦連勝した謎の棋士も、じつはアルファ碁の進化版でした。
なぜ、そんなに早く、地力をつけることができたのか。将棋や囲碁のAIに詳しい、公立はこだて未来大学の松原仁教授は、AI技術のひとつ、ディープラーニング(深層学習)を組み込んだことで、アルファ碁が、自分で自分を鍛え上げ、プロ棋士を上回る「大局観」を身につけたため、と分析します。
松原教授によると、同じAIでも、将棋とアルファ碁では、目指したものが違うといいます。この10年間、将棋AIが磨いてきたのは、どこまで先を見通すか、その先読み、深読みの力でした。通常、14~15手先までというプロ棋士の読みに対し、いまの将棋AIは、ときに20手以上先まで読むことができるといいます。この先読み力が、トップ棋士と互角に戦う棋力のもとになっている、というのです。
松原仁教授(撮影・田中郁也)
これに対し、アルファ碁が手に入れたのは、「深く読む能力というよりも、ぱっと盤面をみたときに、どこがいま大事なのかを見極める能力」だと松原教授はいいます。「人間でいえば、直感とか、大局観といわれるものが、何百万回にも及ぶ、AI同士の自己対局で培われ、人間に追いつき、追い越したのです」
それぞれの駒に異なる動かし方のルールがある将棋と違い、囲碁は、白と黒の石で陣地を取り合うゲームです。そんなシンプルなルールであることも、勝つための手順や法則を自分自身で導き出していく深層学習に向いていたと松原教授はみています。
もともと深層学習は、グーグルの「ネコ認識」が注目を集めたように、画像(イメージ)認識が得意分野のひとつです。盤面に置かれた白石と黒石の配置をイメージとして読み取り、ここから陣地を広げるには、どんな手が望ましいかを判断するのは、ある意味、お手のものだったともいえるでしょう。
こうした「自己学習」する能力を身につけた深層学習の登場で、AI技術の役割は、従来とはまったく異なるものになった、とマサチューセッツ工科大のマックス・テグマーク教授(宇宙物理学)は指摘します。
マックス・テグマーク教授(撮影・田中郁也)
「Good Old Fashioned AI(古き良き時代のAI)」、略して「GOFAI」。テグマーク教授がそう呼んでいる従来型のAIの場合、その「知能」とは、「実は、そのプログラムを開発した技術者やプログラマーの『知能』の反映にすぎなかった」と、テグマーク教授は指摘します。
どんな手順で計算し、答えをだすか。音や画像をどう見分けるか。そのルールや原理は、あらかじめプログラムとして書き込まれ、コンピューターに指示されていたからです。だから、1997年、チェスのチャンピオンを破ったのも、「そのプログラムと、コンピューターの計算スピードの賜物だ」というのです。
一方、最新のAI技術は、「プログラマーが賢い必要はない」と教授はいいます。「大量のデータを与え、繰り返し自分で学習させることで、AIは、まるで子供が一から言葉を覚えるように、どんどん賢くなっていく。わたしたちは、知をデザインする技術を手にいれたのです」
しかし、同時に、新たな課題も生じます。「なぜAIがその答えをだしたのか、きちんと検証できない構造を持ち込んでしまった」と、いうのです。「たとえば人間の子供がどうやって言葉を覚えていくか。わたしたちは、脳の中の神経細胞がどう働いているのか、その仕組みを解明できていません。脳細胞の仕組みをまねた深層学習Aも同じです。その内部で、どんな分析、計算、判断をしたか。なぜ、そんな答えを出したのか。よくわからないのです」
急速な進化を遂げたAIは、どんな変化を私たちの暮らしや社会にもたらそうとしているのか。新たに生じた課題はなにか。どう向きあっていく必要があるのか――。8日発行のGLOBE「人工知能」特集は、4人の記者が各地をめぐり、様々な角度から、AIの現状や近未来の姿、課題について考えてみました。ぜひ手にとって、ページを繰ってみてください。 (田中郁也)
アルファ碁の強さとは 深層学習で身につけた「大局観」 -- 人工知能を愛せますか? -- 朝日新聞GLOBE
http://globe.asahi.com/feature/side/2017010600001.html
松原教授によると、同じAIでも、将棋とアルファ碁では、目指したものが違うといいます。この10年間、
将棋AIが磨いてきたのは、どこまで先を見通すか、その先読み、深読みの力でした。通常、14~15手先
までというプロ棋士の読みに対し、いまの将棋AIは、ときに20手以上先まで読むことができるといいます。
この先読み力が、トップ棋士と互角に戦う棋力のもとになっている、というのです。
これに対し、アルファ碁が手に入れたのは、「深く読む能力というよりも、ぱっと盤面をみたときに、
どこがいま大事なのかを見極める能力」だと松原教授はいいます。
「人間でいえば、直感とか、大局観といわれるものが、何百万回にも及ぶ、AI同士の自己対局で培われ、
人間に追いつき、追い越したのです」
アルファ碁の強さとは 深層学習で身につけた「大局観」 朝日新聞GLOBE
http://globe.asahi.com/feature/side/2017010600001.html
松原教授によると、同じAIでも、将棋とアルファ碁では、目指したものが違うといいます。この10年間、
将棋AIが磨いてきたのは、どこまで先を見通すか、その先読み、深読みの力でした。通常、14~15手先
までというプロ棋士の読みに対し、いまの将棋AIは、ときに20手以上先まで読むことができるといいます。
この先読み力が、トップ棋士と互角に戦う棋力のもとになっている、というのです。
これに対し、アルファ碁が手に入れたのは、「深く読む能力というよりも、ぱっと盤面をみたときに、
どこがいま大事なのかを見極める能力」だと松原教授はいいます。
「人間でいえば、直感とか、大局観といわれるものが、何百万回にも及ぶ、AI同士の自己対局で培われ、
人間に追いつき、追い越したのです」
Is Google DeepMind's Go win a turning point for AI research? | World Economic Forum
https://www.weforum.org/agenda/2016/03/is-google-deepminds-go-win-a-turning-point-for-ai-research?utm_content=buffer6f868&utm_medium=social&utm_source=twitter.com&utm_campaign=buffer
Written by
Sam Shead
Technology Reporter, Business Insider
Published
Wednesday 16 March 2016
Share
Latest Articles
Here's how to turn resolutions into reality, according to an expert
Rebekah Boynton and Anne Swinbourne6 Jan 2017
The Fourth Industrial Revolution disrupted democracy. What comes next?
William H. Saito 6 Jan 2017
Worried about AI taking your job? It's already happening in Japan
Dave Gershgorn 6 Jan 2017
More on the agendaFurther reading arrow
Google DeepMind's AI has won the fifth and final game of Go against human world champion Lee Sedol.
Lee played as black for the first time in the tournament — possibly to try and confuse the AlphaGo AI — but he still lost.
The victory marks the end of a week-long Challenge Series tournament in South Korea that has caught headlines across the world.
It's a major milestone for artificial-intelligence research: Go is a simple game but has been notoriously difficult for computers to master because of the sheer number of potential moves. Go players believe the game relies on intuition as a strategy.
While AI programs began being able to beat humans at chess decades ago, the best Go players in the world have always been able to outsmart Go-playing software — until now.
Go is a two-player, turn-based strategy game. Each player puts down either black or white stones in an attempt to outmaneuver and surround the other player. It's easy to pick up but takes years to master.
Demis Hassabis, the CEO and cofounder of Google DeepMind, said in a statement: " In the past ten days, we have been lucky to witness the incredible culture and excitement surrounding Go. Despite being one of the oldest games in existence, Go this week captured the public’s attention across Asia and the world.
"We thank the Korea Baduk Association for co-hosting the match, and thank all of you who watched. And of course, we want to express our enormous gratitude towards Lee Sedol, who graciously accepted the challenge and has been an incredible talent to watch in every game. Without him we would not have been able to test the limits of Alpha.
He continued: "We wanted to see if we could build a system that could learn to play and beat the best Go players by just providing the games of professional players. We are thrilled to have achieved this milestone, which has been a lifelong dream of mine. Our hope is that in the future we can apply these techniques to other challenges — from instant translation to smartphone assistants to advances in health care."
【AI】ポーカーでもプロに圧勝 人工知能技術を駆使したポーカーのコンピューターソフト「DeepStack」©2ch.net
1 : 白夜φ ★@無断転載は禁止 ©2ch.net2017/03/04(土) 00:05:19.81 ID:CAP_USER
AI、ポーカーでもプロに圧勝
「直感」を磨く?
【ワシントン共同】カナダ・アルバータ大などのチームは、人工知能(AI)技術を駆使したポーカーのコンピューターソフト「ディープスタック」がプロを相手に圧勝したと米科学誌サイエンスに2日発表した。
AIは近年、人に勝つのが困難とされた囲碁でも勝利を収めるなど進歩が著しい。
ポーカーは相手の手札が見えず、展開を読むのが難しいため、勝つには囲碁並みの複雑な判断が必要と考えられていたが、「直感」を磨いて武器にしたという。
不十分な情報の中で判断を迫られるポーカーで勝利する技術は、軍事戦略の立案や、病気の治療方針の決定で応用が期待される。
▽引用元:共同通信 2017/3/3 04:00
https://this.kiji.is/210109600304072188
▽関連
DeepStack: Expert-level artificial intelligence in heads-up no-limit poker
Matej Morav?ik1,2,*, Martin Schmid1,2,*, Neil Burch1, Viliam Lisy1,3, Dustin Morrill1, Nolan Bard1, Trevor Davis1, Kevin Waugh1, Michael Johanson1, Michael Bowling1,†
+ See all authors and affiliations
Science? 02 Mar 2017:
DOI: 10.1126/science.aam6960
http://science.sciencemag.org/content/early/2017/03/01/science.aam6960.full
2 : 名無しのひみつ@無断転載は禁止2017/03/04(土) 00:28:20.28 ID:wq53fxUa
100% ではないのには変わりはないんだから
戦いに大敗北したり、患者が死んだりしたら
誰が責任を負うのか?ってハナシになるよなぁ...
3 : 名無しのひみつ@無断転載は禁止2017/03/04(土) 00:29:31.41 ID:xDXhw3Oo
記事はアブスト読んだだけで書いたな。
本文はモロに数学の内容だから、科学ニュース板住人には読んでもさっぱり判らんからな。
4 : 名無しのひみつ@無断転載は禁止2017/03/04(土) 00:31:39.18 ID:S5QTB7sN
ピューターがヤマカン言い出したら終わりだろwww
5 : 名無しのひみつ@無断転載は禁止2017/03/04(土) 00:52:15.89 ID:Be/yGXRC
接待になってないな
6 : 名無しのひみつ@無断転載は禁止2017/03/04(土) 01:30:04.71 ID:YCNSPZDm
トランプの5枚のカードの組み合わせなんて52C5で有限だし
自分の札と相手の捨て札を見れば、相手の持ってるカードの組み合わせは
はるかに低い数になる。
その中で自分の手札より強い役が存在する割合なんか簡単にはじき出せる。
あとは、AIお得意の学習とやらで癖とか傾向とかを学べば、勝率は上がるよ。
>>3の言ってる数学の内容ってのは、想定されるすべての組み合わせを計算しない
→処理時間を○秒以下にするアルゴリズムなのかな?
7 : 名無しのひみつ@無断転載は禁止2017/03/04(土) 01:32:13.94 ID:35/yUFLk
118 : 名無しのひみつ@無断転載は禁止2017/02/17(金) 02:38:38.62 ID:O6aJ4Qo6
>>11
1996年将棋年鑑
『Q.コンピューターがプロ棋士を負かす日は?』
米長邦雄「永遠になし」
加藤一二三「こないでしょう」
大内延介「当分こない」
久保利明「来世紀」
郷田真隆「いつかはくる。ただし人間を超えることはできないと思う」
青野照市「プロの仲間入りはできても、トップは負かせない」
中原誠「だいぶ先とは思いますがくるはずです」
谷川浩司「私が引退してからの話でしょう」
羽生善治「2015年」
平藤「ゲームセンターで2回負けた」
【人工知能】Googleの最強囲碁AI「AlphaGo」全勝!世界最強棋士も敵わず [無断転載禁止]©2ch.net
1 : 曙光 ★2017/05/27(土) 16:03:53.90 ID:CAP_USER9>>2>>24
最強囲碁AI「AlphaGo」全勝 世界最強棋士も敵わず
ITmedia NEWS 5/27(土) 15:34配信
「The Future of Go Summit」(中国・浙江省(せっこうしょう))で5月23日(現地時間)から開かれている、囲碁世界レーティング1位の柯潔(カ・ケツ)九段と、米Google傘下DeepMindの囲碁AI「AlphaGo」の3番勝負。
27日に最終局第3局が行われ、柯潔九段の投了によりAlphaGoが勝利した。第1局、第2局ともにAlphaGoが勝利し、世界最強の棋士でもAlphaGo相手に勝ち星を上げることはできなかった。
【画像】第1局から第3局までの対戦結果
AlphaGoは2015年10月に、欧州大会で3回優勝した樊麾(Fan Hui)二段に5戦5勝し、ハンデなしで人間を初めて破った囲碁AIとして注目される。2016年5月には世界トップ棋士の李世ドル九段との5番勝負で4勝1敗し、その実力を知らしめた。
この時のAlphaGoのハードウェアは、CPUサーバを1202台、GPUサーバを176台使用する構成だったという。
今回のAlphaGoは、年次開発者会議「Google I/O 2017」で発表された新世代の「TPU(Tensor Processing Unit)」を1台使用する構成で挑んだという。
https://headlines.yahoo.co.jp/hl?a=20170527-00000030-zdn_n-sci
関連
【国際】米グーグルの囲碁AI「アルファ碁」、世界最強の中国囲碁棋士に第1局で勝利 [無断転載禁止]©2ch.net
http://asahi.2ch.net/test/read.cgi/newsplus/1495603095/
1名無し名人2017/05/27(土) 15:28:18.31ID:6GLy1662>>466>>498
◆通常対局
5/23 午前11:30~午後6:30 柯潔vsAlphaGo 1局目 白番AlphaGoの半目勝ち
5/25 午前11:30~午後6:30 柯潔vsAlphaGo 2局目 黒番AlphaGoの中押し勝ち
5/27 午前11:30~午後6:30 柯潔vsAlphaGo 3局目
柯潔 0勝-2勝 AlphaGo
◆ペア碁
5/26 午前9:30~午後1:30 古力+AlphaGo vs 連笑+AlphaGo
◆相談碁
5/26 午後2:30~午後7:30 陳耀燁&時越&羋昱廷&唐韋星&周睿羊 vs AlphaGo
http://events.google.com/alphago2017/
https://www.youtube.com/channel/UCP7jMXSY2xbc3KCAE0MHQ-A
前スレ https://tamae.2ch.net/test/read.cgi/gamestones/1495758380/
112名無し名人2017/05/27(土) 17:08:50.96ID:XX10YoCi>>123>>127>>492
https://deepmind.com/research/alphago/alphago-vs-alphago-self-play-games/
これやね10局あがってる
113名無し名人2017/05/27(土) 17:09:15.46ID:6GLy1662>>121>>126
今後について、
まず、今回の対局のアルファ碁の思考内容などを順次公開していきます。
またアルファ碁の自己対戦の棋譜(15局分)を近いうちに公開します。
世界中の囲碁ファンにとって、役に立てれば幸いです。
今年中には(今年後半には)アルファ碁に関する新たな論文を発表します。
去年の論文をもとに多くの人がそれぞれのバージョンのアルファ碁を作っていますが
今回の論文でさらに強いアルファ碁を作ってもらえると期待しています。
研究開発チームはアルファ碁のアルゴリズムをさらに発展させて汎用性のあるプログラム、
例えば病気の治療などに有用な人工知能を開発することに向かいます。
実際にどんなことができるようになるか、待ち遠しい気がしています。
114名無し名人2017/05/27(土) 17:09:32.94ID:XX10YoCi
あ、でてたww
115名無し名人2017/05/27(土) 17:10:58.13ID:6y8cqOD0>>130
ていうかマジでalphago倒せるのは人間には世界中探しても無理でalphagoだけってわけか
恐ろしいわ
車との速さ勝負とかパソコンと暗算勝負とか言われたらまぁ...ってなるけど
上の例は強さの原理とか強さの程度が分かるんだけどここが謎だからなあ
116名無し名人2017/05/27(土) 17:11:12.58ID:XX10YoCi>>119
世紀の囲碁祭りが終わったなww
117名無し名人2017/05/27(土) 17:12:33.27ID:4pPQDuWW
サンクス
全部で1日10局ずつで全部で50局見せてくれるみたいだな
118名無し名人2017/05/27(土) 17:13:11.88ID:3PRF+XFG
今日は結局何目差だったの?
119名無し名人2017/05/27(土) 17:14:49.84ID:+6emwpVO
>>116
最後まで日本囲碁界が無視されてワロタw
120名無し名人2017/05/27(土) 17:16:33.55ID:q3hZGgNl>>131
とりあえず10局棋譜並べしたけど、星には三三全部入る勢いだな
なんと黒番三連星があった!
全体的に意味不明の手が多いな
人間が真似するのは難しいな
121名無し名人2017/05/27(土) 17:17:37.44ID:Y81lcxY2
>>113
fifteenじゃなくてfiftyね。
近いうちじゃなくて、10局はあの発言直後に公開で、毎日10局ずつ追加
122名無し名人2017/05/27(土) 17:19:03.25ID:XX10YoCi
>>118
ツベ解説者は途中では3目さくらいっていってた
123名無し名人2017/05/27(土) 17:21:45.23ID:BV1BhlGn
>>112
すごいなこれ
124名無し名人2017/05/27(土) 17:24:42.29ID:oeOrQaHQ
これはすごい
今回の対人戦のどの碁より、Alphagoの自己対戦の棋譜の方が断然おもしろい
133名無し名人2017/05/27(土) 17:39:26.70ID:9b7WcHw6
10局中白番の8勝2敗か
やっぱコミ7目半は多すぎるんだな
141名無し名人2017/05/27(土) 17:46:47.34ID:9IKoehe+
>>134
今回の3番勝負はアルファ碁の予想手を交えた検討動画を作って
その検討にはコジェにも参加してもらう
動画は後日公開する、って最後のセレモニーでいってなかったか
142名無し名人2017/05/27(土) 17:47:14.06ID:cUY2UVYW
チェス…IBMスパコン
囲碁…(CPUサーバ1202台GPUサーバ176台)
将棋…スマホ
146名無し名人2017/05/27(土) 17:50:41.11ID:91qn9GBK>>171
DeepMind AlphaGoの次の動き
https://deepmind.com/blog/alphagos-next-move/
149名無し名人2017/05/27(土) 17:53:35.99ID:91qn9GBK
DeepMindの次の目標
・脳を模倣した自律汎用AI開発
・エネルギー問題の解決
・病気の治療
・新薬の創造
・新素材の創造
・宇宙を解明
158名無し名人2017/05/27(土) 18:02:36.77ID:9IKoehe+
Masterの碁を小林光一が気に入って、美しいといって並べてるって話があるくらいだから
あのレベルになると意味がわかった気になるくらいは少なくともできるんだろうな
自分には意味不明だけど
159名無し名人2017/05/27(土) 18:03:53.91ID:j4YHtNIV
星→かかり→コスミつけ→三々から侵入
は面白い筋だと思ったけど最終的には侵入した石全部取られてるのね (;^∀^)
160名無し名人2017/05/27(土) 18:05:04.97ID:iJvpzgx4
石田芳夫も治勲もマスターの対局全局並べてるのが偉いわ
161名無し名人2017/05/27(土) 18:07:40.02ID:/A2U89cN
>>90
グーグルも凄いが
真に凄いのは開発者の「デミスハサビス」
グーグルが750億を出してでも欲しがった超天才プログラマー
囲碁攻略の次は医療分野
166名無し名人2017/05/27(土) 18:13:30.44ID:j4YHtNIV
AlphaGo VS. 人間 だと弱い石を作らない打ち回しの印象が強いけど
AlphaGo同士だとカオスになるのね。
人間が調和を求める打ち方をするからなのかな?
167名無し名人2017/05/27(土) 18:13:50.08ID:ozcVmdBH
医療分野といってもレントゲン画像からガン細胞見つけたりする限定的な分野なら使えるし実用化も近い
174名無し名人2017/05/27(土) 18:20:03.51ID:ozcVmdBH>>190
>>168
超性能ハードで1ヶ月259万対局
1日8万6000対局
1時間3600対局
1分60対局
ちょうど1秒に1対局だから
平均250手として1手0.004秒かな?
175名無し名人2017/05/27(土) 18:20:51.85ID:QDT3TN0U>>184>>185>>189>>193>>285
これで完全に撤退されたら
DeepMindは囲碁界を徹底的に荒らして回っただけで終わってしまう
182名無し名人2017/05/27(土) 18:26:12.10ID:9b7WcHw6
アルファ碁同士の自己対戦、8局目の黒番のアルファ碁が一番乱れてるように見えるね
最後のコウ争いの最中にそっぽの場所に打ってコウ解消されてから
全体を取りにいったけど236手目のグズミで目を二つ作る手と
右上の7子を切り離される手を見合いにされて投了
負け確だから暴走したのか単純にグズミが見えてなかったのかは分からんが
相対的にコウ争いが苦手なのはあんまり変わってないっぽい
187名無し名人2017/05/27(土) 18:37:42.88ID:6EMaswIr
We’re also working on a teaching tool - one of the top requests we’ve received throughout this week.
The tool will show AlphaGo’s analysis of Go positions, providing an insight into how the program thinks, and hopefully giving all players and fans the opportunity to see the game through the lens of AlphaGo.
アルファ碁による棋譜解析ツールを開発してるそうだ
206名無し名人2017/05/27(土) 18:55:58.92ID:oKHPj7QH
柯潔迷妹自媒体? @kejie_fans 2時間前
ファン・フイさん:大会後、チームは柯潔九段にAlphaGoの予想変化図を見せ、一緒にこの三局を検討する予定。
この検討過程も映像化し世界中の囲碁ファンにお見せします。
柯潔九段は最初は驚き、そして横の連笑八段に笑顔を向けた。
柯潔 vs AlphaGo part4 [無断転載禁止]©2ch.net
https://tamae.2ch.net/test/read.cgi/gamestones/1495866498/112-
550名無し名人2017/05/28(日) 01:40:52.60ID:vFaZHBYK
アルファ碁については今年後半、処理効率の改善やより幅広い課題に対応するための手法について、詳しく解説する学術論文を公開する。
「他の開発者がこのバトンを引き継いでくれることで、アルファ碁の進化を利用した強力な囲碁プログラムが生まれることを願う」としている。
リクエストが多かったというアルファ碁の考え方の筋道が見られるようにする「研究ツール」の開発に取り組む。
また、「世界中の囲碁ファンに向けて特別な贈り物をしたい」として、アルファ碁の自己対局の一部、50局を選んで公開する。
https://headlines.yahoo.co.jp/hl?a=20170527-00000112-mai-soci
ハサビスがインタビューで言ってたとおりだよ。
勝ちの確率が最大になる手を選ぶようにプログラムしているのであって、
石の差が最大になるように勝ちの手順を選ぶわけではない。
序盤から中盤で有利になったとたんに緩んだようにみえたり、疑問手に見えるような手は
差が縮まっても、あるいはリードした分の一部を犠牲にしても全体として勝つ確率が最大、
つまり負ける可能性が最小、逆転される可能性が最小の手を選んでいるだけ。
だから途中で差が縮まったように見えても、逆転の目は全くない変化に入っているということ。
内容的には大差だよ。何度やっても勝てないレベルだよ。
【柯潔】完全が100なら私は50でAlphaGoは100 [無断転載禁止]©2ch.net
25コメント4KB
全部
1-100
最新50
★スマホ版★
■掲示板に戻る■
★ULA版★
1名無し名人2017/05/25(木) 17:15:30.40ID:qrYrdSm4
柯潔が press conference で尋ねられてそう答えてた。
AlphaGo は神だって
2名無し名人2017/05/25(木) 17:29:24.39ID:rm7L8syG>>6
本当に人間のトップ棋士は50もあるんですかねぇ
3名無し名人2017/05/25(木) 17:29:24.62ID:lkxxUNjE
AlphaGodかよ
4名無し名人2017/05/25(木) 17:39:24.21ID:6bq5CFrT
将棋の棋士たちにせめてこの百分の一の潔さがあれば救われたものを・・・・。
5名無し名人2017/05/25(木) 18:09:25.06ID:fvO+lMbb
100mを10秒で走れる人と20秒で走れる人で競うようなものか
6名無し名人2017/05/25(木) 23:10:06.71ID:Ofz2d0Lb
>>2
藤沢秀行「碁の神様が解ってるのを100としたら
自分が解ってるのは、せいぜい5か6だ」
7名無し名人2017/05/25(木) 23:10:22.81ID:ebSzHcNf
もう3年後には今のアルファ碁より3目強いのが出てくるのかな
8名無し名人2017/05/25(木) 23:17:43.19ID:8ozz43jp
こみにしてな
9名無し名人2017/05/26(金) 00:45:17.59ID:KPVPtbz9
カケツさんは80くらいある
謙虚だな
10名無し名人2017/05/26(金) 00:49:51.90ID:2dW/daJO
「コントロールルームの表示では、50手の段階まで柯潔の手は完璧だったと分析されていました。そして、その後の100手までは新しいAlphaGoと、これまでのどの対戦相手よりも競り合っていました。本当に接戦だったのです」Demis Hasabis
カケツも神やんw
https://deepmind.com/research/alphago/alphago-vs-alphago-self-play-games/
これやね10局あがってる
113名無し名人2017/05/27(土) 17:09:15.46ID:6GLy1662>>121>>126
今後について、
まず、今回の対局のアルファ碁の思考内容などを順次公開していきます。
またアルファ碁の自己対戦の棋譜(50局分)を近いうちに公開します。
世界中の囲碁ファンにとって、役に立てれば幸いです。
今年中には(今年後半には)アルファ碁に関する新たな論文を発表します。
去年の論文をもとに多くの人がそれぞれのバージョンのアルファ碁を作っていますが
今回の論文でさらに強いアルファ碁を作ってもらえると期待しています。
研究開発チームはアルファ碁のアルゴリズムをさらに発展させて汎用性のあるプログラム、
例えば病気の治療などに有用な人工知能を開発することに向かいます。
実際にどんなことができるようになるか、待ち遠しい気がしています。
【AI】アルファ碁同士の棋譜公開 碁界騒然「見たことない」★2 [無断転載禁止]©2ch.net
1 : ばーど ★2017/06/02(金) 20:34:33.73 ID:CAP_USER9>>35>>75
アルファ碁同士の棋譜公開 碁界騒然「見たことない」
2017年6月2日17時24分
http://www.asahi.com/articles/ASK610JLRK50UCVL03K.html?iref=sptop_8_01
世界最強棋士との三番勝負で完勝した囲碁AI(人工知能)「アルファ碁」を開発したグーグル傘下の英ディープマインド社が、対局に備えて積み重ねたアルファ碁同士による自己対戦の棋譜50局を公開した。棋士の理解を超える着手の連続に、「こんな碁はいまだかつて見たことがない」と碁界は騒然としている。
革新的な技術「ディープラーニング(深層学習)」を導入したアルファ碁は、高段者の棋譜を写真のように画像として読み込み、各局面に応じた好手を学習。人間の残す棋譜だけでは教材が足りず、アルファ碁同士が自己対戦を繰り返して能力を高めたが、その棋譜はほとんど非公表だった。
アルファ碁は5月23~27日、中国の世界最強棋士、柯潔(かけつ)九段を3戦全勝で圧倒。その後、ディープマインド社は「囲碁ファンへのスペシャルギフト」として棋譜50局を自社のホームページに公開した。
手数が進んだ特殊な状況に限り有効とされていた「星への三々(さんさん)入り」を序盤の早いうちに互いに打ち合ったり、双方の石がぶつかり合って手抜きがしにくい接触戦のさなかに戦いを放置して他方面に転戦したり。これまでの常識では考えられない着手の連続にプロ棋士らは驚愕(きょうがく)した。
世界戦制覇の実績を持つ中国の…(残り:318文字/全文:837文字)
★1が立った時間 2017年6月2日17時24分
前スレ
http://asahi.2ch.net/test/read.cgi/newsplus/1496393135/
https://ja.m.wikipedia.org/wiki/イロレーティング
イロレーティング
ページの問題点
イロレーティング (Elo rating) とは、チェスなどの2人制ゲームにおける実力の測定値(レーティング)の算出法である。「イロ」とはこの算出法を考案した、ハンガリー生まれでアメリカの物理学者であるアルパド・イロ(英語版)に由来する。
チェスでは国際チェス連盟の公式レーティングに採用されるなど、強さを示す指標として用いられている。日本では、将棋倶楽部24などで、イロレーティングを簡素化した算出法を採用している。
目次
算出方法 編集
イロレーティングでは、次の3点を基本とする。
ゲームの結果は一方の勝ち、一方の負けのみとし、引き分けは考慮しない(0.5勝0.5敗と扱うものとする)。
200点のレート差がある対局者間では、レートの高い側が約76パーセントの確率で勝利する。
平均的な対局者のレートを1500とする。
3人の対局者A,B,CについてAがBに勝利する確率を{\displaystyle E_{AB}}、BがAに勝利する確率を{\displaystyle E_{BA}}などと定める。対局者間の勝率について次のような仮定を置く。
{\displaystyle {\frac {E_{AC}}{E_{CA}}}={\frac {E_{AB}E_{BC}}{E_{BA}E_{CB}}}}
例えばAがBに平均3勝2敗、BがCに平均5勝6敗の成績だとすれば、AはCに平均15勝12敗(=5勝4敗)でなければならない。
2人の対局者A、Bの現在のレートを{\displaystyle R_{A}}およびR_{B}としたとき、それぞれが勝利する確率{\displaystyle E_{A}}、E_{B}は以下の式で算出される。
{\displaystyle E_{A}={\frac {1}{1+10^{(R_{B}-R_{A})/400}}}}
{\displaystyle E_{B}={\frac {1}{1+10^{(R_{A}-R_{B})/400}}}}
実際に何局か対局した結果、Aの勝ち数が{\displaystyle S_{A}}であった場合、Aのレートを以下のように補正し、新たなレート{\displaystyle R_{A}^{\prime }}とする({\displaystyle E_{A}}は各対局の勝利する確率を足し合わせる)。
{\displaystyle R_{A}^{\prime }=R_{A}+K(S_{A}-E_{A})}
ここで、Kは定数値であり、プロレベルでは16、通常は32をとることが多い。
例として、レーティング1613の対局者Aが5局戦い、レート1609の対局者に敗れ、1477の対局者と引き分け、1388の対局者に勝ち、1586の対局者に勝ち、1720の対局者に敗れたものとする。このときのAの勝ち数{\displaystyle S_{A}}は2.5(2勝2敗1引き分け)となる。上記の式より、{\displaystyle E_{A}}の合計は 0.506 + 0.686 + 0.785 + 0.539 + 0.351 = 2.867 と算出されるので、対戦後の新たなレートは 1613 + 32×(2.5 − 2.867) = 1601 となる。
擬似的な算出方法 編集
日本での囲碁や将棋のオンライン対戦サイトでは、参加者の棋力を示すためにレーティングを用いているところもある。これらの多くはイロレーティングではなく、対戦後のレーティングを簡単に算出できる方法を用いている。
2人の対局者A、Bの現在のレートを{\displaystyle R_{A}}およびR_{B}とし、AがBに勝った場合、レーティングの変動値\Delta R({\displaystyle R_{A}}は\Delta Rだけ増加し、R_{B}は\Delta Rだけ減少する)は各サービスごとに以下のようになる。
将棋倶楽部24・近代将棋道場
{\displaystyle \Delta R=16+(R_{B}-R_{A})\times 0.04}
小数点以下は四捨五入。上記で算出した\Delta Rが1未満のときは1に、31を超えるときは31になる。
ただし0未満ならびに32以上の場合は先手の権利が下手と確定している。 詳細については割愛する。
TAISENの囲碁対局
{\displaystyle \Delta R=12+\{R_{B}-(R_{A}\pm H)\}\times 0.03}
※Hはハンデ(置き石やコミの調整による)ごとに定められた点数。
小数点以下は四捨五入。上記で算出した\Delta Rが1未満のときは1になる。
ただし、極端にレートが離れたもの同士が対局する場合などには、特例が設けられている。
問題点 編集
FIDEの公式レーティングは1985年ごろから年に数点ずつインフレを起こしており、これがグランドマスターをはじめタイトル保持者の増加につながっている。
インフレ問題を解決するため、標準偏差を考慮したグリコレーティングが考案され、一部の団体(オーストラリアチェス連盟(英語版)など)、インターネット上のチェスサイトで利用が始まっている。
チェスにおける棋力評価の算出についてはチェスのレーティング(英語版)を参照。
文献 編集
The Rating of Chessplayers, Past and Present (1978), Arco. ISBN 0-668-04721-6 - 考案者による解説
関連項目 編集
Chessgraphs.com - Compare chess players' rating histories with FIDE data back to 1970
ロジスティック分布
ランキング
チェス世界ランキング
ワールドフットボールイロレーティング
執筆の途中です この項目は、ゲームに関連した書きかけの項目です。この項目を加筆・訂正などしてくださる協力者を求めています(ポータル ゲーム)。
ノート
藤井くんの仮想レートに対する26連勝確率を計算してみた。
レーティングは
http://kenyu1234.php.xdomain.jp/rate.php
を借りてきて、対局者のレートは対局時ではなくこの表のものを使用。
横山アマは R1500 とした。
仮想レート|26連勝確率
1700 0.00235176%
1750 0.02026063%
1800 0.12053144%
1850 0.51668351%
1900 1.66862646%
1950 4.24140112%
2000 8.84032029%
2050 15.67600130%
2100 24.41856345%
2150 34.32982760%
2200 44.54286583%
2250 54.30881339%
2300 63.12108035%
2350 70.72555818%
2400 77.06733388%
たとえ藤井くんがR2000あったとしても僥倖だわな
>>440
単純に
https://ja.wikipedia.org/wiki/%E3%82%A4%E3%83%AD%E3%83%AC%E3%83%BC%E3%83%86%E3%82%A3%E3%83%B3%E3%82%B0
の式を適用しただけだよ。
25連勝確率=EA(1)*EA(2)* ... *EA(25)
違うよ。アルファ碁は1か月間に2900万局を超える自己対戦で強くなっていったんだけど、
ある局面で自分の弱点(例えば自分が不利なのに有利だと判断するとか)は、
自分がその弱点部分をスルーするのと同時に対戦相手も(自分自身なので)スルーしてしまう。
で、弱点が修正されることなく残ってしまう。
(だからトッププロと対戦して自己対戦で修正できない弱点をさらけ出してもらう必要があった)
今年のバージョンではそういう弱点を自己対戦で修正するためのアルゴリズムを開発して
組み込んである。だからセドル戦のようなことはおこらない。
master戦はそれを確認するための、トップ棋士との60戦60連勝だった。
アルファ碁が苦手としていたあらゆる局面を自己対戦で修正し、人間には負けないレベルに
到達したことを証明したんだ。
自己対戦で自分の間違いを修正することができる、このことがこれからのAIの開発と進歩で
もっとも大きなポイントになるし、グーグルはその第一歩を歴史に残した。
これが大事。
学習しているのはポリシーネット部分。
学習というのは、ぶっちゃけ、ネットワーク内部のウェイトを計算により微調整する事。
ポリシーネットは、学習対象の他、過去に学習対象に負け越したものが一杯プール
されていて、それらが対戦相手となる。自己と対戦し続けているわけではない。
最初に学習対象のネットワークを用意したら、それのコピーをプールに入れる。
その2つで対戦させて強化学習。勝ち越しの閾値を超えたら、学習対象のコピーを
プールに追加して、2つのネットワークとランダムに対戦させる。勝ち越し閾値を超え
たら、同様にコピーをプールに追加して、3つのネットワークとランダムに対戦させる・・・。
コピーをプールに追加するのを世代と呼ぶ。
最初の論文で、10000世代まで強化学習させたと書いてあったはず。
最初の一番弱い奴までプールに入れてあるのは、>>92で言うところの自己対戦に
よる過学習を防ぐためのもの。対戦相手の多様性を保つための工夫。
また、ε-greedyを採用して、学習対象のネットワークは、一定確率で敢えてランダム
に手を着手して、今の手が最善なのか、違うかを確認している。これも過学習防止策。
これらは特別なアルゴリズムでもなければ、「特定の弱点を修正するための方法」は
大抵、別の大きな弊害をもたらす事から、そういう付け焼刃な対処をしていないと、
考えるのが自然。
好きな駒、強いて言えば・・・藤井四段インタビューを動画で - ニッカン芸能!
geino-smp.nikkansports.com/.../news_article_photo.zpl?...
2017年6月18日 ... 対局後、インタビューに答える藤井聡太四段=17日、大阪市福島区、安冨良弘撮影( 朝日新聞社) ... 好きな駒は? 「難しいですけど、強いて言えば『角』です。使い方 によってかなり働きが違ってくるので、難しさとともに、面白さを感じます」
https://1.bp.blogspot.com/-a3riPKt2c6g/Vz1-wT_uo5I/AAAAAAAA-7o/-2h_PEzflFIn4Jln2U-JewUmf7T5tEtKACLcB/s1600/hinotori2772a.gif
手塚治虫愛のコスモゾーン冒頭を見ると実感できるのだが、人工知能は人間の教育に力を発揮するべきだろう。
https://1.bp.blogspot.com/-a3riPKt2c6g/Vz1-wT_uo5I/AAAAAAAA-7o/-2h_PEzflFIn4Jln2U-JewUmf7T5tEtKACLcB/s1600/hinotori2772a.gif
囲碁を知らない子供が二人
二つのAIが半年教育する
子供が対戦し
勝った子供の教師AIが勝者
デバイスが大事になる
すごい
アルファ碁、さらに進化=自己学習のみで最強に―グーグル
https://headlines.yahoo.co.jp/hl?a=20171019-00000005-jij-eurp
昨年3月、世界最強とされる韓国人棋士に圧勝した囲碁人工知能「アルファ碁」の改良版「アルファ碁ゼロ」が開発され、旧アルファ碁との対局で100戦100勝の成績を挙げた。
旧アルファ碁は過去のプロ棋士の対局を学習し、アルファ碁同士の対局(自己対局)を繰り返して進化を遂げたが、アルファ碁ゼロは「お手本」を必要とせず、自己対局だけで世界最強の能力を身に付けた。
論文は19日付の英科学誌ネイチャー電子版に掲載された。
人工知能(AI)はさまざまな分野で目覚ましい進化を遂げているが、最初の学習には人間の専門家による知識が必要で、データ化や入手が難しいなどの問題があった。
米グーグル傘下の英グーグル・ディープマインド社が開発したアルファ碁ゼロは、過去の対局などの学習用データ入力なしに、白紙の状態から自己対局を繰り返して、指し手や盤面の評価を自ら学んでいくプログラムを搭載。
旧アルファ碁では、人間の指し手の学習と訓練に数カ月かかっていたのに対し、アルファ碁ゼロは数日間、約500万回の自己対局で性能を向上させた。
プログラムの改良により、計算に用いるコンピューターチップの数も少なくて済むという。
以下、月刊碁ワールド2017年11月号より
…
星合 世界電脳囲碁オープン戦に参戦した時は夢百合杯の時のバージョンに手を加えたん
ですか?
加藤 まず15・0から15・3にバージョンを上げました。今の囲碁AIはバリューネ
ットワーク(以下・VN)が……。
星合 VNとは?
加藤 失礼。VNとは、ある局面で黒から見た勝率がどのくらいかをはじき出してくれる
、ニューラルネットワーク(人間の神経細胞を模した情報処理システム)の一種でディー
プラーニングによつて作られます。これこそがアルファ碁がコンピュータ囲碁界に持ち込
んだ革命的手法なんです。
星合 アルファ碁や最近の囲碁AIの強さの秘密というわけですね。
…
加藤 もう少しVNを説明しましょう。ある局面があって、将来どちらが勝つかをシミュ
レーションします。つまり予測します。その予測をするためにポリシーネットワーク(以
下。PN)というものを使います。このPNがないとVNも作れないんです。
星合 …‥はい。
大橋 難しいところですけど、大切なところです。
加藤 ここからPNについて話します。まずディープラーニングとは機械学習の手法です
。細かいことは省きますが、簡単に言うと「人間の真似」をするのがとても上手くなるん
です。例えば一番有名なのは、ディープラーニングによってAIが動物や人間などの顔を
区別・認識できるようにさせたものでしょう。画像にはパンダであるとか、ゴリラである
とかを記した画像=ラベル付けと言われる=を何万、何十万と与えてディープラーニング
させると、その特徴を学習し、ゴリラやパンダの顔を、AIが人間の真似をして区別でき
るようになります。
…
加藤 このPNを使ってある局面から最後まで打たせると、人間同士で打った時に勝つか
負けるかが分かるわけです。手を選ぶのに乱数を使うので、その結論は一つに限りません
から、それを何万回と実行すると、その局面で勝つ確率が求まります。これを対局中に毎
回行うのは時間がかかりすぎるので、プログラマーは諦めていました。ところがデイビッ
ド・シルバーさんはこの結果を別途、他のニューラルネットワークに覚えさせることを思
いつきます。アルファ碁で実践して成功したわけです。
…
星合 モンテカルロってなんですか?
加藤 モンテカルロとはモナコ公国にある有名なカジノの名前で、そのため、欧米では乱
数を使うアルゴリズム(手法)の名前の頭にモンテカルロとつける慣習があるんです。
大橋 囲碁で乱数を使っている手法ですよ、と示すのにモンテカルロ碁と表記するという
ことですね。
加藤 2006年にモンテカルロ革命と呼ばれるぐらい囲碁ソフトの作り方が変わりまし
た。それまではプログラマーが「アキ三角は悪い形である」というプログラムを作ったり
、部分的な死活探索を行わせていました。盤面を形勢判断する評価関数も人間が手作りし
ていたんですね。ところが厚みなどの評価ができない。例えば厚みが最終的にどのぐらい
の地になるかなどがわからないわけです。
星合 今の囲碁AIはむしろそうした厚みの判断がすごいですよね。何が変わったんです
か。
加藤 いい質問ですね。1990年にドイツのマックスプランク研究所のベルント・ブリ
ュークマン博士が「途中で判断するのが難しければ最後まで打たせればいい」と考えたわ
けです。つまリシミュレーションを使って、両者がそれなりに最後まで打ったらどうなる
かをプログラムの中で行ったわけです。ある局面で適当な候補手を、それぞれ乱数を使っ
て1000回シミュレートして一番勝率の高い手を選ぶわけです。これが原始モンテカル
ロ法です。
星合 しらみつぶしにシミュレーションするのですか。
加藤 いいえ、詳細は省きますが、乱数を使って手をランダムに選んで打つんです。その
ため、初めはとても不正確です。このシミュレーションの妥当性、実際に起きる手順をど
の程度真似できるかが強さに決定的に影響します。あと、本探索というのもモンテカルロ
碁を語る上で重要です。木探索ではある局面から有力そうな手を例えば10手ぐらいに絞
り込みます。1図のAの部分です。その絞り込んだ手をシミュレーションするのがBの部
分です。先ほども述べたようにシミュレーションは不正確なものなので木探索を行って手
を絞ることでより正確になるわけです。
https://i.imgur.com/axR6gtZ.jpg
大橋 この図の形が木のように見えるのでモンテカルロ木探索と呼ばれるわけですね。
加藤 このモンテカルロ木探索を囲碁AIに採り入れたのがCrazy Stoneとい
うソフトを作ったレミ・クーロン氏です。2007年にCrazy Stoneはコンピ
ュータ。オリンピアードの九路碁部門で優勝してモンテカルロ法は脚光を浴びたのです。
…
https://i.imgur.com/Jqcy529.jpg
加藤 囲碁って、手順がとても大切ですよね。例えば2図のような攻め合いでは、いきな
り白aと打たず、まず根本を白bとツイでから次に白aと打つのが手順です。ところがシ
ミュレーションする時、こうした手順について工夫・プログラミングしないと白aと突っ
込む手を多発してしまうんです。他にはウツテガエシとかオイオトシについてもチェック
するプログラムを入れています。こうした工夫がZenの頃からたくさんいれてあり、こ
れが強みなんです。
…
星合 アルファ碁に苦手なことってあるんですか?
加藤 具体的に言うと、一手の差で勝敗がひっくり返る局面です。
星合 戦いとか攻め合いとかですか。
加藤 全部ではなく「勝敗がひっくり返る」ような攻め合いや戦いです。そのような局面
はアルファ碁にとって「不利な局面である」と評価するようにVNを作ってあります。真
正面から戦わないのはずるいように見えるかもしれませんが、人間も苦手な局面を避けて
得意な局面に持っていくことはありますよね。
…
加藤 AIが人間と打つときはVNを使ってできるだけ序盤でリードしてそのまま押し切
ります。ところが囲碁AI同士が打つと、どちらも序盤が強いので、あまり差がつかない
んです。したがって、中盤の戦闘力が勝敗のカギを握ります。世界電脳囲碁オープン戦の
時、予選で絶芸とCGIに負けてしまったので、本戦の時はVNの比重を下げてシミュレ
ーションの比重を上げて中盤の戦闘力を上げたんです。DZGは先ほど話したようにシミ
ュレーションで戦いに強くなるよう工夫をしてあります。それは長い開発期間の積み重ね
が背景にあります。最近始めた囲碁AIはそれがないので、VNの比重を下げても強くな
らない。
…
大橋 棋士の間では、攻め合いに弱点はあるものの、DZGの中盤戦の評価は高いですよ。
星合 そうですよね。でも、ようやく加藤さんの言うことが分かってきました。ディープ
ラーニングしたAIは自分で考えることができるようになったのだと思っていたのですが
、まだ人間の真似をしているだけなんですね。
加藤 まさにその通り。そこを誤解している人が本当に多い。「人間の真似が非常に上手
い」と言ったのはそういうこと。ディープラーニングは人間の直感を機械に移植しただけ
なんです。いわゆる仮説推論や抽象化など人間のいう賢さは、ディープラーニングでは得
られないのです。
…
星合 もう少し聞いてもよろしいですか。これからDZGはどこに向かっていくんですか
?
加藤 劇的に強くなることはないでしょう。これ以上強くするには技術的にもうひとつブ
レイクスルー(飛躍的に進歩すること)が必要です。私としては棋士の先生方の勉強に役
立てていただきたいですね。私自身囲碁が大好きなので、世界戦で日本に勝ってもらいた
いという気持ちももちろんありますが、それ以上に最先端の技術を広く一般に安く提供す
るエンジニアとしての性(さが)があります。ぼくはお酒の杜氏さんで例えるんですが、
杜氏さんの勘を科学的に分析して広く使えるようにすることで美味しい日本酒が安く買え
るようになった。囲碁界もDZGを使って、プロもアマも強くなってほしい。
…
王銘エン
アルファ後レポート#3 人間の興味は「強さ」だけではありません
…
ある意味で人間の代わりにAIが山を登ってしまった今、すそ野にも人間が楽しめること
がたくさんあることに気がつきます。究極の強さは一つしかないが、弱さには無限な種類
があります。登る山は一つしかないが、すそ野での遊び方はいくらでもあるのです。
https://lh3.googleusercontent.com/--RA2YzXJWXk/Wf7xpDoGtPI/AAAAAAABV4c/7Vdh3oJr3u8WtXDpK_GDBd16yaHUnLAyQCHMYCw/s640/blogger-image-30638813.jpg
2図、白1のカケツギは李世ドルシリーズの時に、アルフア碁がよく打った手です。黒がa
に応じると、白はすぐbにノゾキ、その後プロ棋士の実戦でもたくさん打たれました。ところ
が、カ潔のシリーズの後の自己対戦50局では、白1は一回も打たれていません。ほとんど
3図、白1の固ツギになりました。
もちろん偶然ではなく、固ツギの方がいいと見ているのです。
強さだけを問題にするなら、新しいバージョンの方が強いので、カケツギは「悪い手」で
あり、とりあえず廃棄処分されないといけません。しかしそれを知っていて、人間はいま
でも2図のカケツギを打ちます。そして面白いことに黒aに受けても、すぐbにノゾく碁が
少なくなってきています。
人間はある手を打つためには、やはり「理由」が必要なのです。自分より「強い」ものの手
だからと言って、それを打つ理由が自分の中になければ、打てるものではありません。
井山の笑い声が不評だったが以下の試みは面白かった
AIと人間は排中律ではない
【DeepZenGo出場】世界ペア碁最強位決定戦「ペア碁方式による”囲碁AI”の研究親善対局」
https://youtu.be/afshKrDykfc
93名無しさん@恐縮です2018/02/18(日) 10:58:22.74ID:3r0YCnIA0
>>58
碁盤に線があるでしょ?
あれが道と思ったらいい
四つある逃げ道を白は塞がれてしまってる状態なんだよ
だから、囲い込まれて殺されちゃうんだよ、その白部隊は
ばっは子 @郡山囲碁スクール (@J_S_Bachko)
2018/03/13 0:48
囲碁は「石で線を引いて輪を作るゲーム。線がつながって輪になるとその中が自分の陣地になる。端も使っていい。石にはそれぞれHPがある。HPが無くなったり、最後まで輪ができなかった石は相手に取られる」
最近はこの説明でだいたい4分で死活までインスト終わって九路1局打てる。囲碁用語一切要らん。
https://1.bp.blogspot.com/-a3riPKt2c6g/Vz1-wT_uo5I/AAAAAAAA-7o/-2h_PEzflFIn4Jln2U-JewUmf7T5tEtKACLcB/s1600/hinotori2772a.gif
手塚治虫愛のコスモゾーン冒頭を見ると実感できるのだが、人工知能は人間の教育に力を発揮するべきだろう。
囲碁を知らない子供が二人
二つのAIが半年教育する
子供が対戦し
勝った子供の教師AIが勝者
デバイスが大事になる
羽生永世七冠もAIの教育面での使用を予想している
https://youtu.be/yCALyQRN3hw
2:35:30
呉清源
https://youtu.be/yCALyQRN3hw?t=3h10m20s
78手目
AlphaGo 第4局78手目
https://youtu.be/yCALyQRN3hw?t=3h10m20s
https://lh3.googleusercontent.com/-U4aYpmb-0yQ/VuX419WNYDI/AAAAAAAA7rk/_S4DgWOS79o/s640/blogger-image--1799271017.jpg
https://1.bp.blogspot.com/-a3riPKt2c6g/Vz1-wT_uo5I/AAAAAAAA-7o/-2h_PEzflFIn4Jln2U-JewUmf7T5tEtKACLcB/s1600/hinotori2772a.gif
手塚治虫愛のコスモゾーン冒頭を見ると実感できるのだが、人工知能は人間の教育に力を発揮するべきだろう。
囲碁を知らない子供が二人
二つのAIが半年教育する
子供が対戦し
勝った子供の教師AIが勝者
名前: 名無しさん@恐縮です
E-mail:
内容:
AlphaGo 第4局78手目
https://youtu.be/yCALyQRN3hw?t=3h10m20s
https://lh3.googleusercontent.com/-U4aYpmb-0yQ/VuX419WNYDI/AAAAAAAA7rk/_S4DgWOS79o/s640/blogger-image--1799271017.jpg
____
https://1.bp.blogspot.com/-a3riPKt2c6g/Vz1-wT_uo5I/AAAAAAAA-7o/-2h_PEzflFIn4Jln2U-JewUmf7T5tEtKACLcB/s1600/hinotori2772a.gif
手塚治虫愛のコスモゾーン冒頭を見ると実感できるのだが、人工知能は人間の教育に力を発揮するべきだろう。
囲碁を知らない子供が二人
二つのAIが半年教育する
子供が対戦し
勝った子供の教師AIが勝者
シチョウとは?
https://twitter.com/tiikituukahana/status/1437685409627049990?s=61
コメントを投稿
<< Home